宏观理解
随着大数据时代的发展,我们慢慢的可以把积累的零散的数据整理起来,让他们之间形成关系,让他们之间有连接。这个工作就是知识图谱。自2015年以后物联网IoT的壮大,“连接”的重要性越来越强。我们不单单的只会去研究数据 本身的含义,还需要去把零散的数据整合起来,让他们可以互相解释对方,互相增加对方的含义。
知识图谱是2012年google提出来的,也被叫做语义网络Semantic Network。知识图谱说白了就是一堆节点和一堆边(或者我们把边称作关系)组成,说起来很像刑侦剧里刑警画的犯罪物证关系网。所以我们也可以 把知识图谱称为多关系图Multi-relational graph。
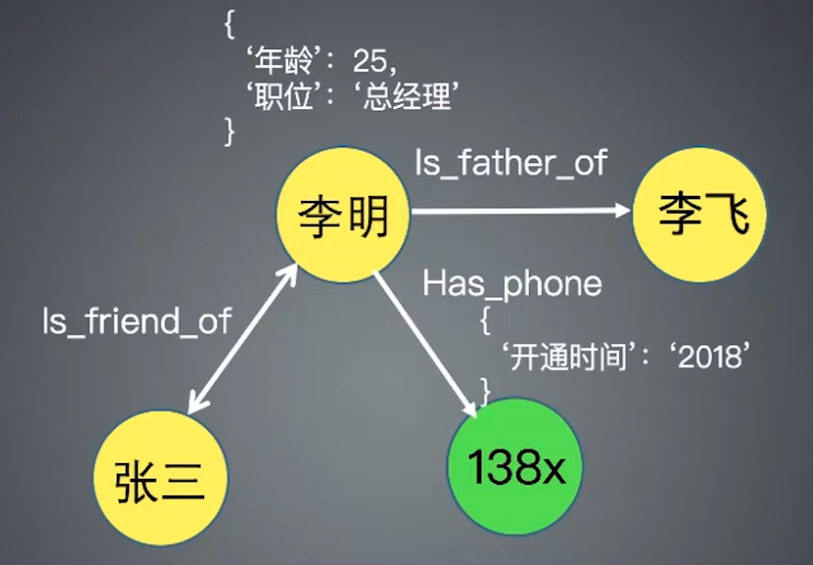
知识图谱由两种东西组成,一个是节点,我们叫实体,指的是现实世界中的任何事物。还有一个叫边,我们叫关系,指的是实体之间的关系。 我们也可以把知识图谱看作是知识库Knowledge base,里面的每两个实体和他们的关系我们称为事实Fact。其中每个实体或者关系都可以有多个属性,如下图中的开通时间和年龄。我们管这种有属性的语义网络叫做属性图Property Graph。
微观分析
知识图谱虽然可以为我们的任务带来额外加持,但是如果盲目使用往往都会白费功夫。在使用之前,我们要先考虑一下它的用处,比如
- 有没有强烈的可视化需求?
比如非技术人员是否会使用到?
- 有没有涉及深度搜索的场景?
比如小明的朋友我们不认为是深度搜索,但是如果是小明的朋友的工作单位我们认为是深度搜索
- 对查询效率有没有实时性要求?
- 是不是数据多样化、解决数据孤岛问题?
- 有没有能力和成本来搭建知识图谱?
需要大量的人力和硬件资源存储的支持
- 有没有一定知识推理的需求
知识图谱的构建流程
- 了解项目定义
- 收集数据
途径有跟多,还是要和项目场景贴合。例如用户的基本数据、行为数据、运营商数据、电商数据、公开的贴吧论坛数据等
- 数据预处理
缺失值、特征选择、整合数据
- 设计知识图谱
需要哪些实体、关系和属性?
- 存储知识图谱
- 应用知识图谱
基于规则的方法 基于概率的方法
- 评估系统
知识图谱的构建方式
- 利用非结构化数据
例如图片、文本、网页、语音、视频等,需要进一步的处理才能被放入知识图谱
如果从网页中自动构建知识图谱,就还需要用到实体抽取、实体识别、关系抽取、实体统一、实体消歧、指代消解、模版匹配等等。是个相对困难的事情,准确率也无法保证。
- 利用结构化数据 具有模式的数据,例如在数据库里的数据
- 利用结构化和非结构化数据
知识图谱的类型
- 开放域知识图谱
例如Freebase, YAGO, Dbpedia。这种图谱的目的只是类似于让大脑有一个基本的认知,不涉及任何专业领域,往往都是根据非结构化数据搭建的。
- 领域知识图谱
含有专业领域的,例如证券、风控、医疗。这些知识图谱的构建一般都是由结构化和非结构化数据组成的。
知识图谱的存储
- 根据自己的需求自己写数据结构
- 使用已有的RDF存储系统
存储的三元组 <李明-age-25>,但是不带有属性
- 使用已有的图数据库系统
可以有属性
- 在已有的开源系统上根据需求改进