宏观理解
当我们在做爬虫或者给定大量的文本,我们很多的需求是从信息中抽取出我们感兴趣的内容。这类的数据我们叫做非结构化数据,我们可以通过信息抽取把非结构化的数据转换成结构化数据。例如我们可以把爬虫爬下来的网页内容中抽取出(公司名称,公司地址)的映射存入数据库中。典型的应用比如知识库的搭建、搜索引擎、对话系统等。
在这个例子中,我们管抽取公司名称叫做抽取实体,例如人名、地名、时间、物质名称(例如商品名、蛋白质、某疾病、某药物)等。我们管抽取公司地址叫做抽取关系,例如公司对应的地址,人对应的工作单位,或者说某药品的组成部分等。
微观分析
那么如何抽取出实体呢?这个领域叫做命名实体识别(NER)。识别的方法有很多:
- 利用规则(比如正则匹配电话号码)
- 投票模型(majority voting)
- 利用分类模型:
- 非时序模型:逻辑回归、SVM等
- 时序模型:HMM、LSTM-CRF、Bert-BiLSTM-CRF等
在做完实体的抽取之后我们才能对抽取出来的实体进行关系抽取。这种关系主要是从属关系的抽取,例如A是一个xx, A属于xxx。也有一些常用的方法:
- 基于规则
例如我们在判断实体A,B之间有没有包含 is-a/such as/including/… 的短句。
优点是准确率很高,也不太需要training data。但是缺点是成本太高、召回率recall不会很好、并且规则数量多了之后,很难筛选和精简这些规则。
- 监督学习
使用分类的方式,可以一般的机器学习模型。比如我们抽取完实体A,B之后我们可以给定几个关系标签来学习。特征我们可以选择来自上下文的词性、实体自身特征、位置和依存文法等。
- 半监督学习
- Bootstrap
可以用于生成新的pattern,缺点是错误率高。
- Distant Supervision
- Bootstrap
- 无监督学习
命名实体
我们围绕着命名实体有四种任务:
- 命名实体识别
- 命名实体消解
- 命名实体链接
- 命名实体关系抽取
命名实体识别
我们用深度学习来做实体识别的好处有很多,比如深度学习是非线性变换的,并且因为深度学习可以端到端,避免了人力设计实体特征。所以在我们拿到一个句子之后,我们直接可以通过深度学习训练词表示,然后再用词表示喂到一个编码-解码器里面。
那么我们就分成三步来看看整体是如何操作的,第一步是学习词向量,第二步是编码器,第三步是解码器。
第一步:学习词向量
我们有三种方式:
- word-level representation
就像我们平时用的word2vec学习的词向量。但是有些不常见的词会被替换成
- char-lever representation
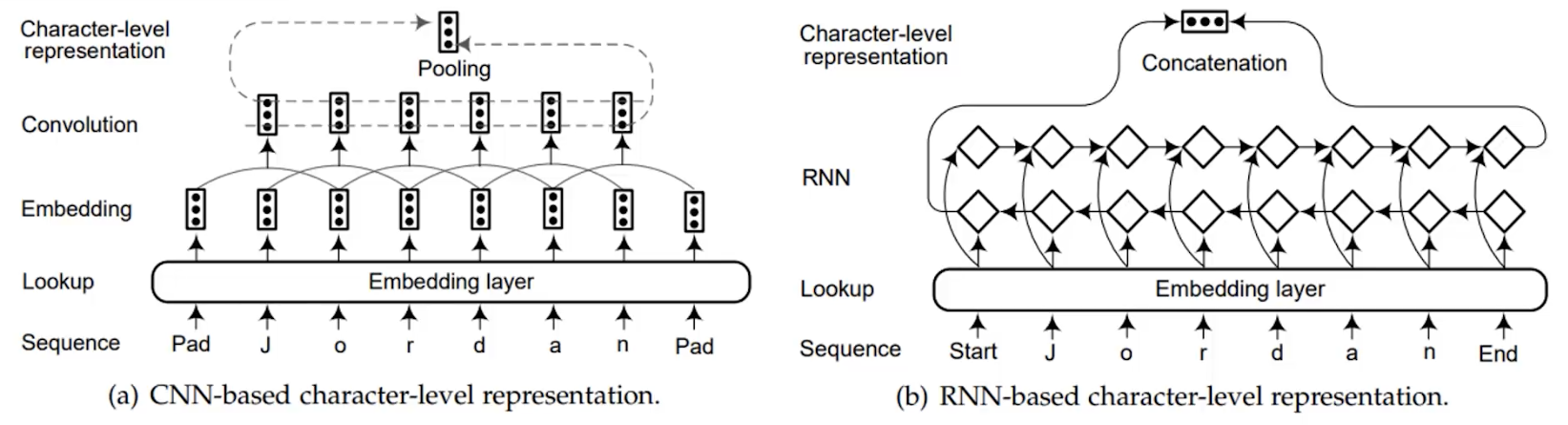
我们把一个单词的每个字母拆分开,像训练每个单词那样去训练每个字母。通常来说字母的表示维度和我们规定的词是相等的,所以最后我们可以把字母的表示经过一些操作比如pooling作为词的表示。 在这里面的embedding layer是随机初始化的,我们通过一个字典来look up初始化向量。
- hybrid representation
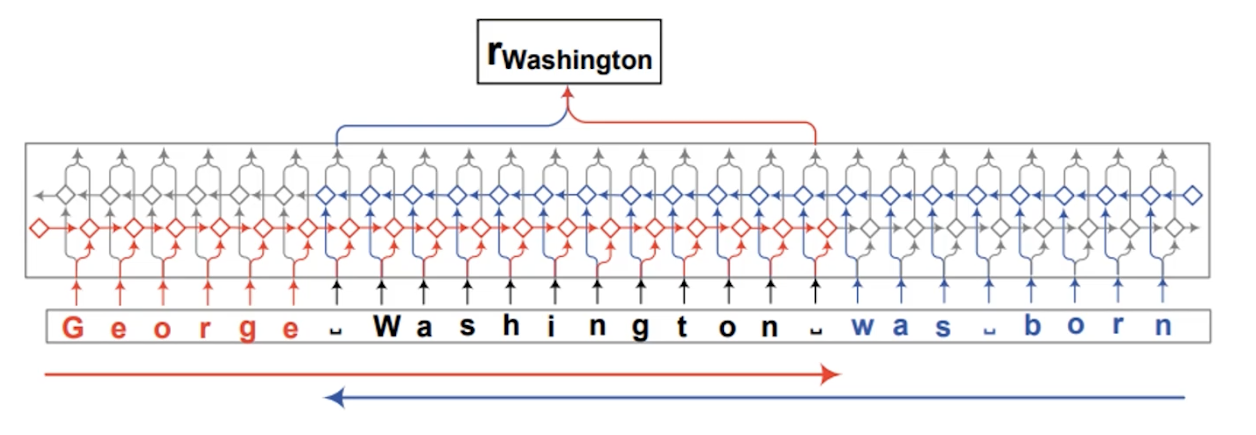
hybrid和之前的区别是,此时我们不需要开始和结束的tag,而是把一整句话同时喂进去,通过一个前向一个后向的LSTM学习完后,那单词对应的几个隐状态拿出来当成最终的词表示。
第二步:编码器
我们有很多种类的模型可以用作编码器,比如RNN,CNN,或者用RNN+语言模型的方法。当然还有一些使用递归神经网络和使用transformer架构的。但是事实证明目前效果比较好的还是RNN+语言模型。
- RNN
用RNN应该是最直观的,喂进去我们学习好的词向量,再喂给双层双向的循环神经网络。但是它的问题是复杂度高,速度慢。
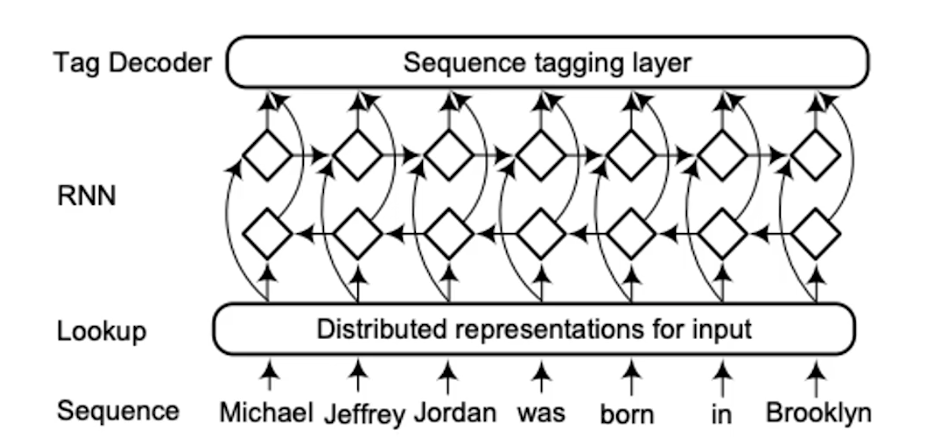
- CNN
随后就有人提议要用CNN来做,这样在喂进去一个句子的时候,每3个词我们可以做一个卷积,然后像tree一样我们在上一层再继续用3个做卷积。
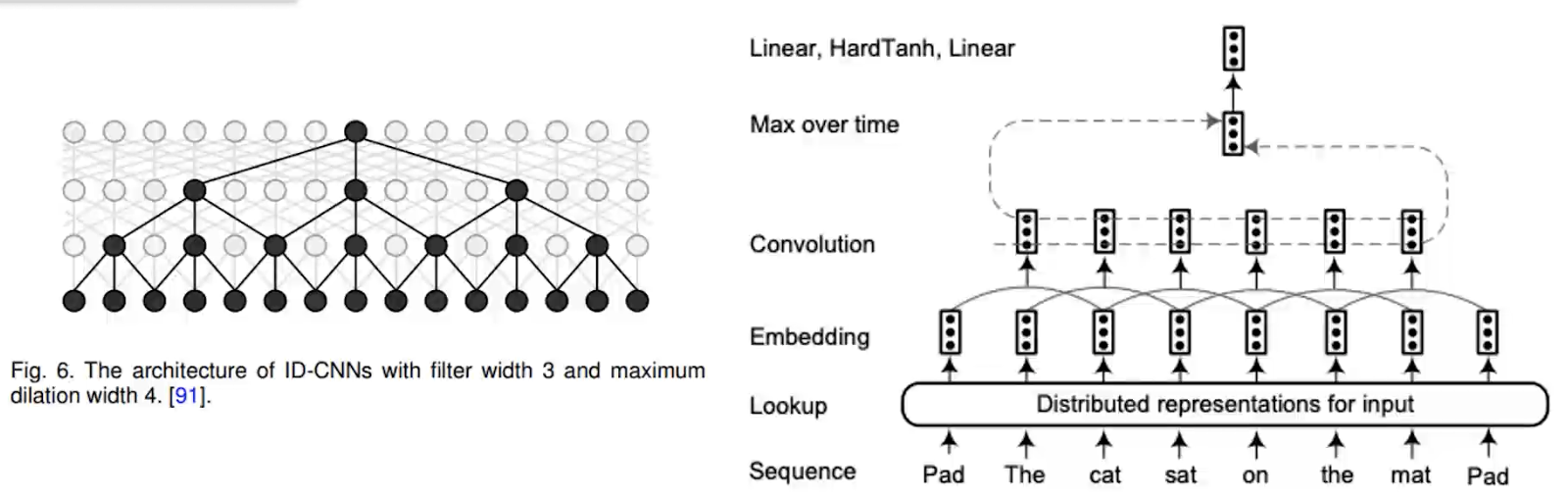
- RNN+语言模型
我们用RNN学习完词向量,然后再加一个双向的语言模型。就是一个multi-task learning,同时预测前面的词、后面的词、词的标签,最后把loss相加共同优化这两个模型。
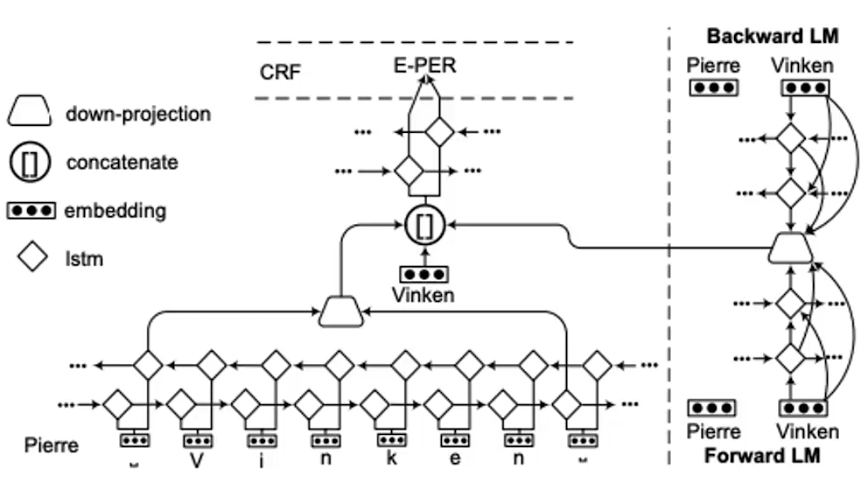
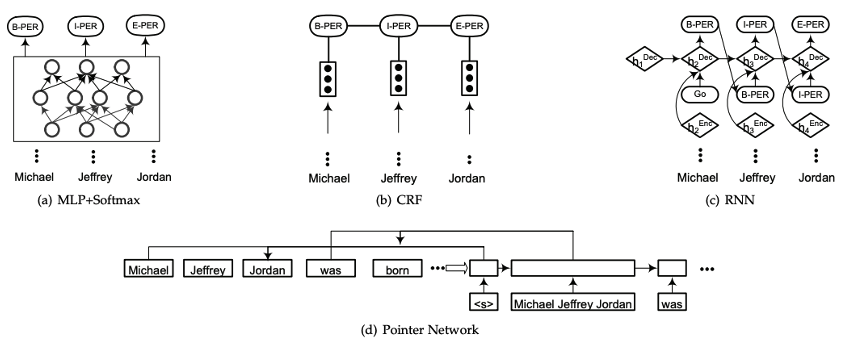
第三步:解码器
这个结构也就很多了:
命名实体消解
实体消解就是在一句话中先找出所有的命名实体,然后再分析哪些命名实体是同一个东西或人。比如“小明发烧了,所以他没去学校”中我们就要找到“他”可以替换成“小明”。这个任务在NLP领域内算是很难很难的,所以在各种任务中都不常见。
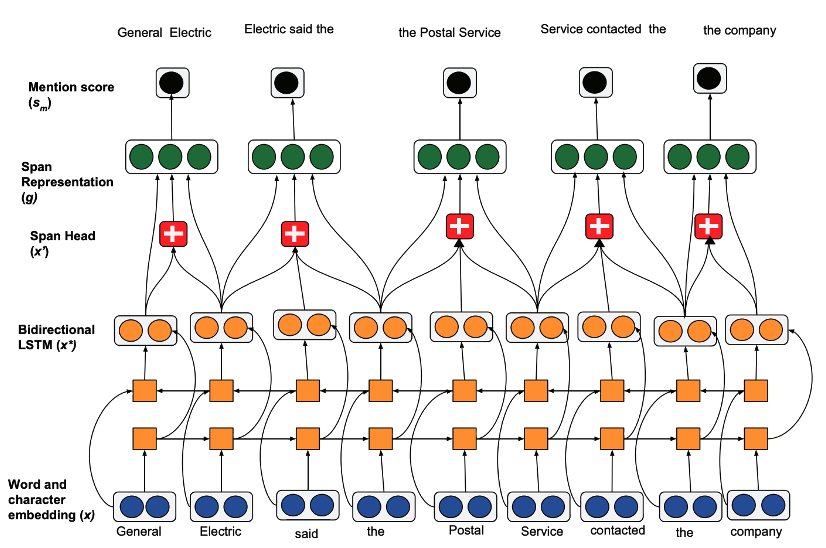
如果必须在任务中加入实体消解,也可以尝试一下这个模型,虽然效果未必会好,但是也别无选择了。。
命名实体链接
这个任务其实也可以叫做实体消歧,就是在有一个文本和一个知识库的前提下,对所有的实体进行链接:
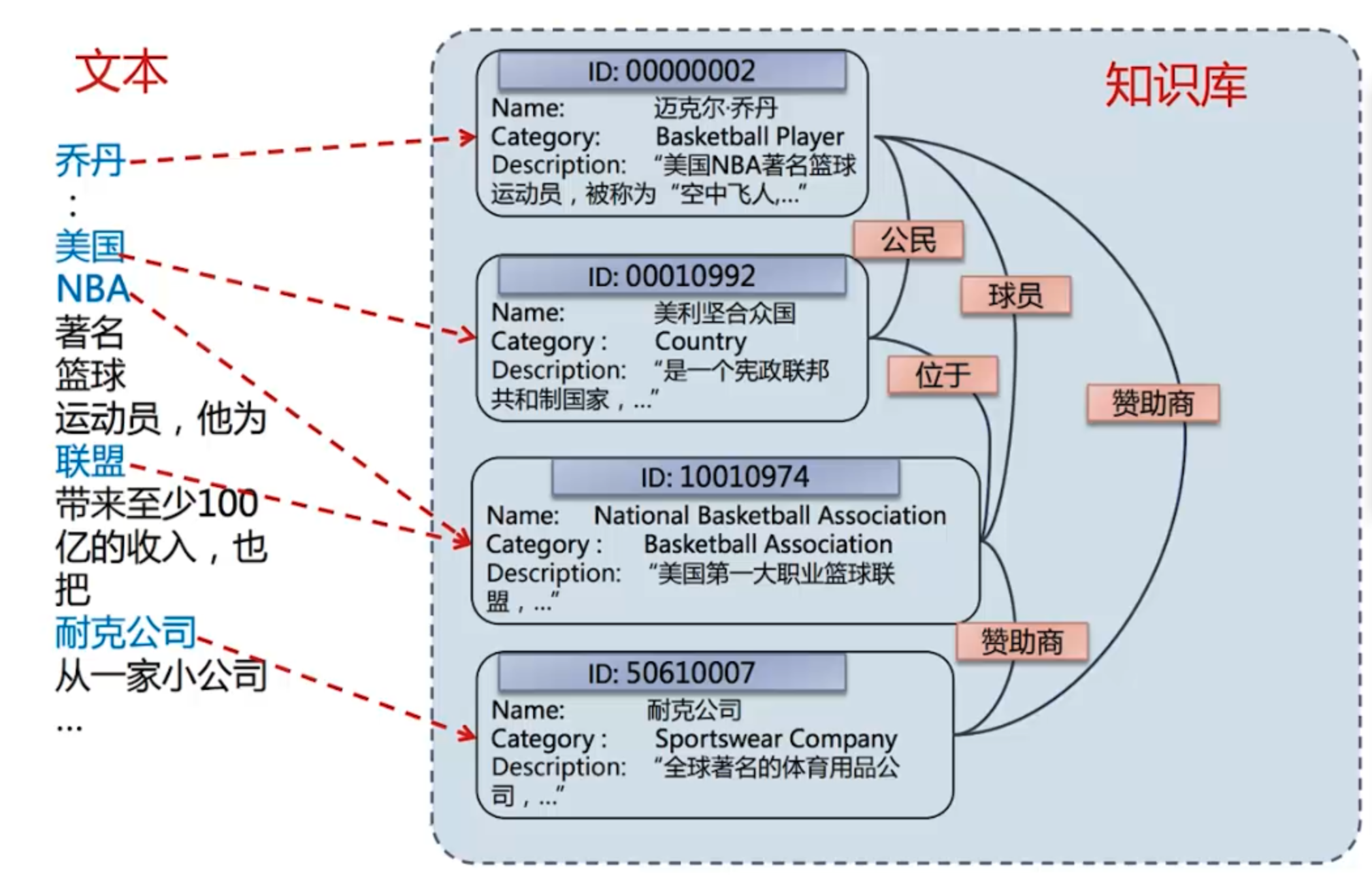
这个任务的应用和实体消解比就非常多了,比如问答系统,文本分析,信息抽取等。
实体链接主要分成三个部分完成:
- 产生候选实体(Candidate Entity Generation): 给定句子当中的entity mention,找出知识库当中匹配度比较高的实体作为候选实体,组成一个候选实体集合M;
- 基于实体字典的匹配
- 基于文档信息扩充候选实体 (某些Mention是首字母缩略词或其全名的一部分)
- 基于搜索引擎的扩展
- 排序候选实体(Candidate Entity Ranking): 对候选实体集合M进行排序/分类,选择出合适的实体。这里主要使用机器学习算法进行分类/排序;
- 可以训练一个分类器来根据mention排序
-
可以用一个概率模型分别计算 P(entity mention,cntent)
- 无法链接预测(Unlinkable Mention Prediction): 出现新的实体,entity mention不在知识库当中就是无法链接到知识库的情况