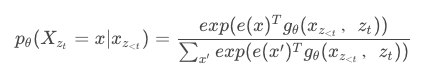宏观理解
XLNet是一种语言模型,是对现有的语言模型进行了一些改进,可以更好的应用在下游NLU任务中。
在语言模型中我们已经见过普通的autoregressive language model,用概率乘积的形式去近似一个条件概率分布。还见过在Bert中的masked language model,试图去预测masked token。 他们之间的区别是autoregressive的模型在训练的时候是只能看到左边的词,无法看到后面的词。虽然在bert中用的是self attention可以看到后面的词的信息,但是在bert预测masked token时,两个masked token之间是独立的,换句话说就是我在预测第二个词的时候并不受第一个预测出来的token的影响。
那我们可不可以把这两种模型的优点融合一下?作者在XLNet中又提出了一个新的优化目标。
微观分析
在介绍XLNet之前我们要先介绍一下Transformer-XL。
我们知道语言模型做的事情就是去近似一个条件概率分布,一开始使用的是LSTM,后来又有了Transformer。但是有一个问题是这些模型的输入都是固定长度的,比如512个token。那么如果我们有一个长于512的句子,就只能做截断。比如我们会把句子分割成每4个token的截断,然后分别把这4个token喂给模型。我们用第一个token来预测第二个,用第一、二个来预测第三个。。。这样循环下去,我们就有了4个loss,然后在优化的时候我们把4个loss的总和进行反向传播。然后再次进行下一个4个token的截断。
这样一听就明显有几个问题,首先就是每个截断之间的关联没有了。如果句子中的第五个词和第一个词有一定关系,这样截断的话他们的关系就不能被模型注意,所以斩断了长序依赖。 在预测的时候同样有一个问题,我们在预测第五个词的时候,模型根本看不到前面的4个,只能瞎猜。 还有就是我们在evaluation中预测第4个词的时候可以把1-3放到模型中,可是如果要预测第5个词,我们又要重新把2,3,4放在模型中,因为前后截断的隐向量是不可见的。
所以Transformer-XL想做的事情就是把前面的截断的隐状态可以传递给后面的截断。
在RNN时代,我们当然同样面临这个问题。人们就会用Truncated BPTT来解决这个问题。也就是我们把第四个token的隐向量传递给下一个截断的第一个,通过这种方式来传递之前的信息。但是在第二个截断进行反向传播 的时候,我们不对第一个截断进行回传,所以叫做Truncated。
我们当然可以把这种套路应用在transformer里面。
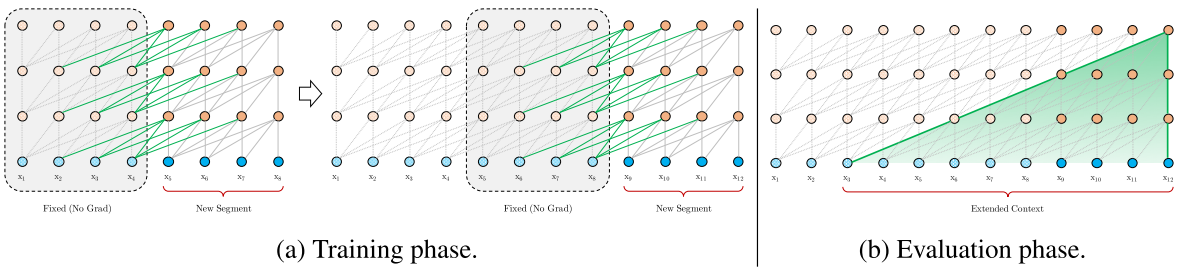
我们在计算第五个词的时候,我们可以缓存下来前面的隐变量,然后利用self attention的机制让第五个词可以直接看到这些隐变量,反向传播的时候我们照样可以对前面的进行停止传播。stop gredient下面公式用SG表示。
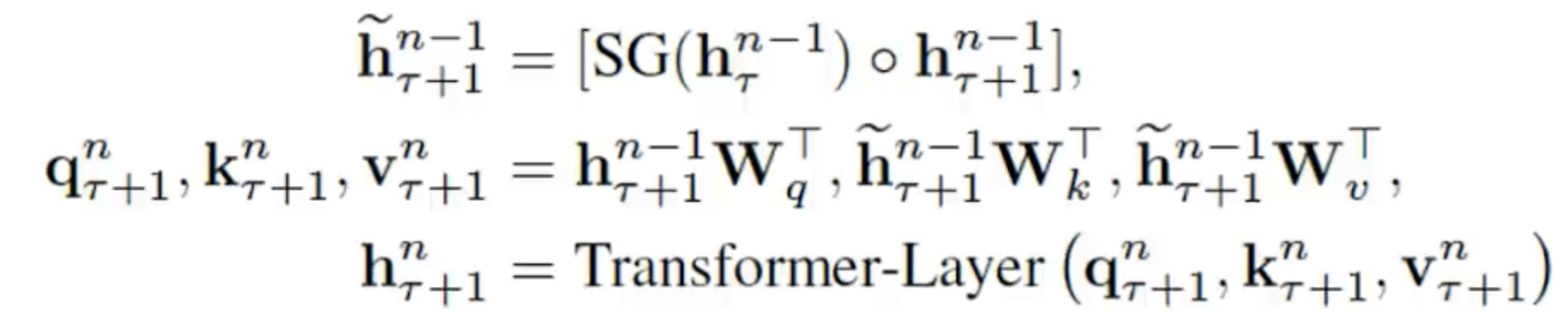
第一步是我们把前一个截断的context和当前截断的context拼接起来,然后在self attention的时候用当前位置的context隐向量去做query,用拼起来的向量去做key和value来计算下一个位置的隐状态。
Transformer-XL除了对长序依赖问题的优化,还有另一个优化,叫Relative positional Embedding相对位置编码。我们之前的transformer为了加入单词的位置信息,引入了绝对位置编码来作为输入的一部分。 但是在长序依赖问题上存在一个问题,就是每个segment截断的相同位置上的token的绝对位置编码是一样的。这样的话就会让模型认为第一和第五个词都是一句话中的第一个词。
在self attention中,我们的query是通过词向量和绝对位置编码相加通过一个query向量相乘得到的:,同理我们的key也是通过乘一个key向量得到的:
那么我们在attention计算权重时,就是把这一个query一个key的输入相乘来计算权重。我们用A来表示这个权重:
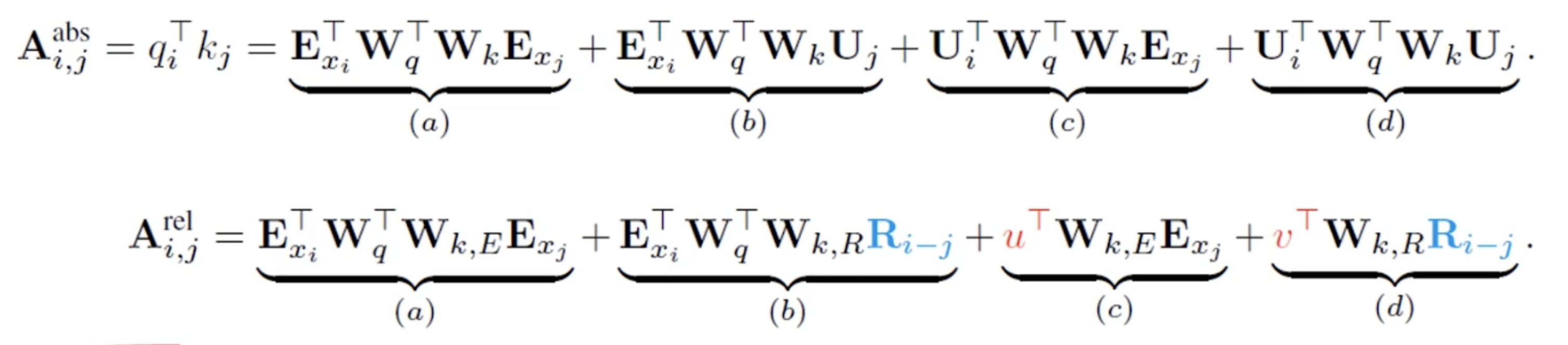
那么我们把计算过程展开就会得到这四个项a、b、c、d。我们可以观察出a项中,是两个词向量之间的乘积,也就是内容上的相关性。d项中完全是位置之间的乘积,也就是表示位置之间的偏移。中间的bc是和位置和词向量都有关。那么我们在修改绝对位置编码的时候,我们可以把b、d中的位置信息转变成i相对于j的位置向量。并且把c、d中的U转变成了可训练的固定参数u和v。为了让他们的分工更加的明确。 实验证明了这种方式的效果会变得更好。
我们把这两个优化加入到self attention中,整个的流程就变成:
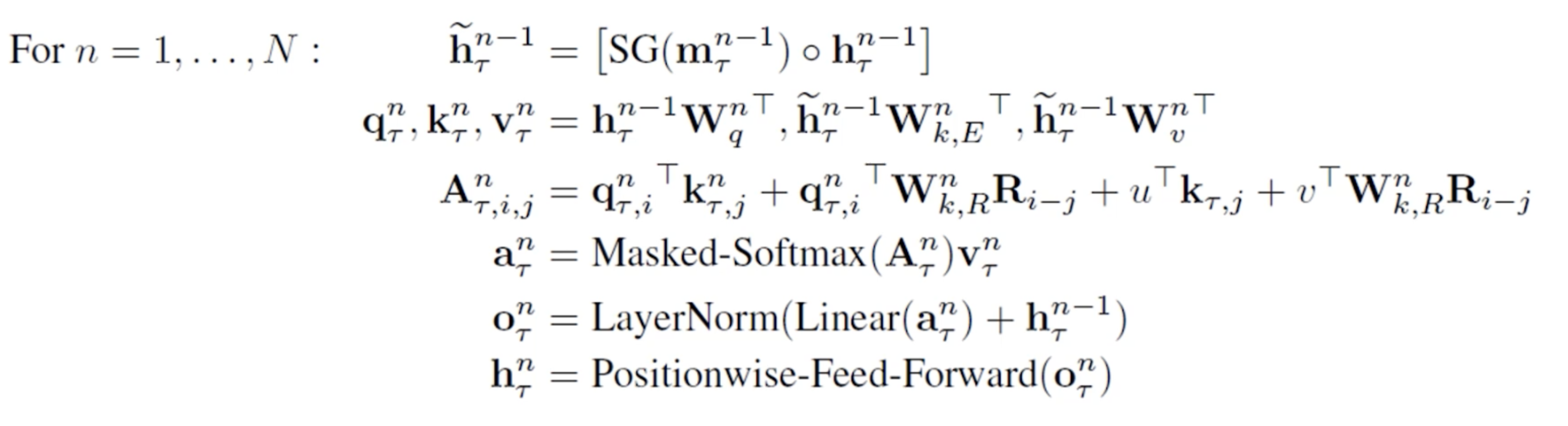
其中m表示缓存memory中的隐状态,至于我们需要多久之前的隐状态相拼接这个就是一个超参数了。
接下来我们就可以去了解一下XLNet是怎么做的更加fancy的。
XLNet
回到XLNet中,作者提出了一个新的优化目标,对于一个序列X =【x1,x2,x3,x4】,我们找出它的全排列,再去做autoregressive model的方式去预测。
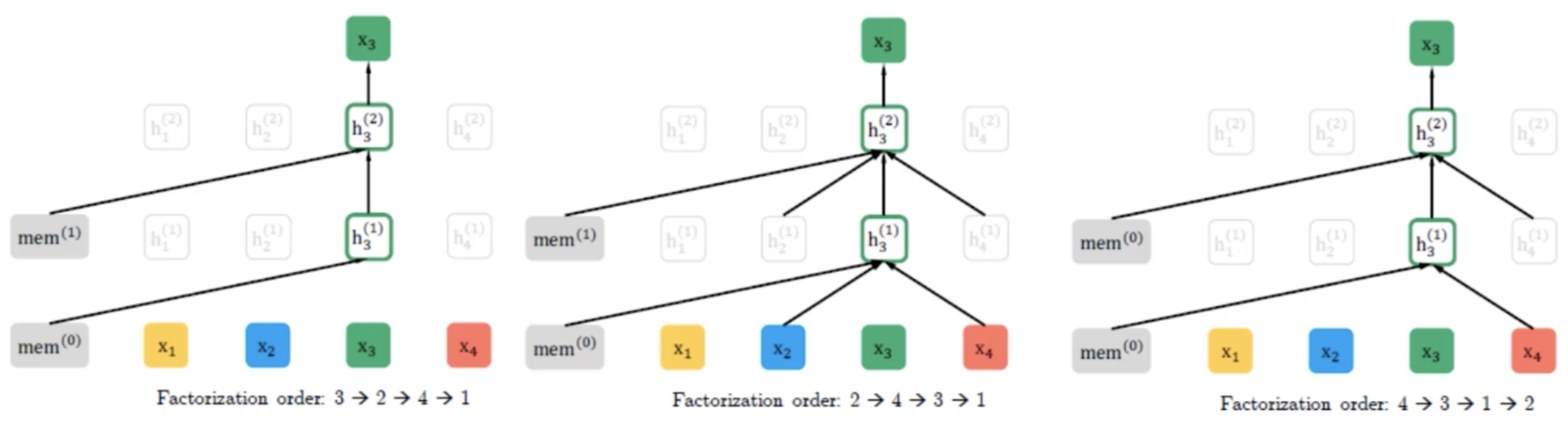
例如图中我们得到的三种全排列方式,我们训练的时候就用第3个词去预测第2个词,用第3、2个词去预测第4个词。。。再用第2个词去预测第4个词,用第2、4个词去预测第3个词。。。
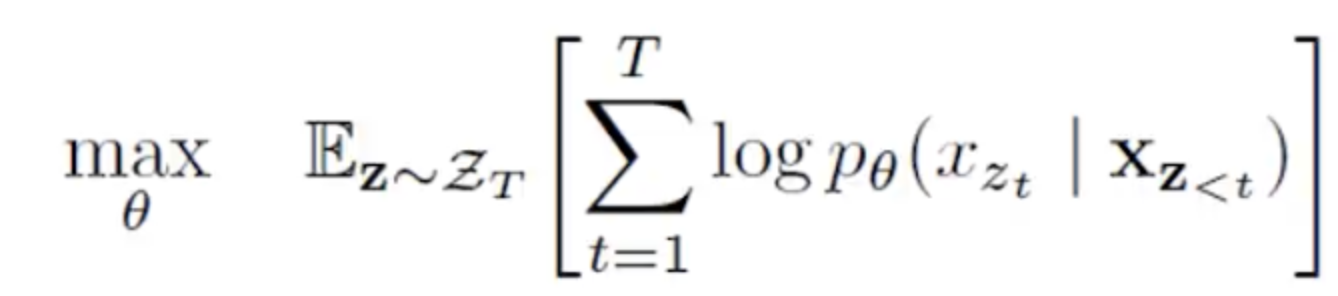
在目标函数中,我们用Z来表示所有的全排列,每次我们都从中随机选取一个排列方式进行优化。
但是我们怎么去参数化这个过程呢?也就是我们需要学习哪些参数呢?如果我们直接把autoregressive的目标函数直接拿过来,我们会缺少位置信息。并且我们希望我们要预测的词,模型已知该词的位置信息和该词之前所有词的位置和内容信息,但是不能知道该词的内容信息。
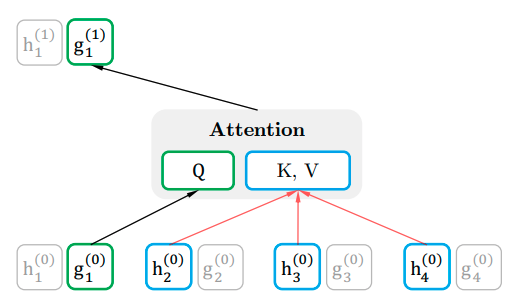
作者提出了一种叫双流自注意力的机制,所谓双流就是我们把之前self attention中的表示方法分成了两个:
- content representation(content stream):用来编码内容信息,计算h的方法和multi-head self attention一样。
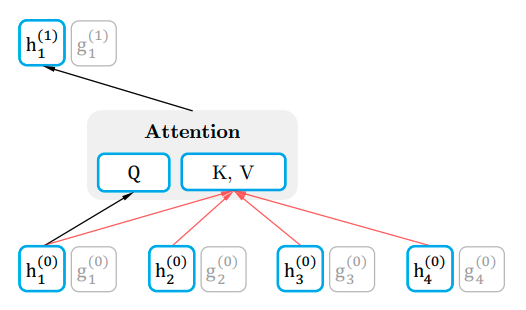
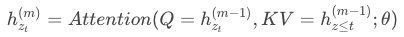
- query representation(query stream):只知道词的位置信息,计算g的方法是每次我们把上一轮的g拿来当作query,其他位置的h当成key和value(不包含当前位置的h)。再通过self attention得到当前的g。
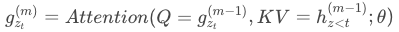
最后我们把这两个过程合并在一起
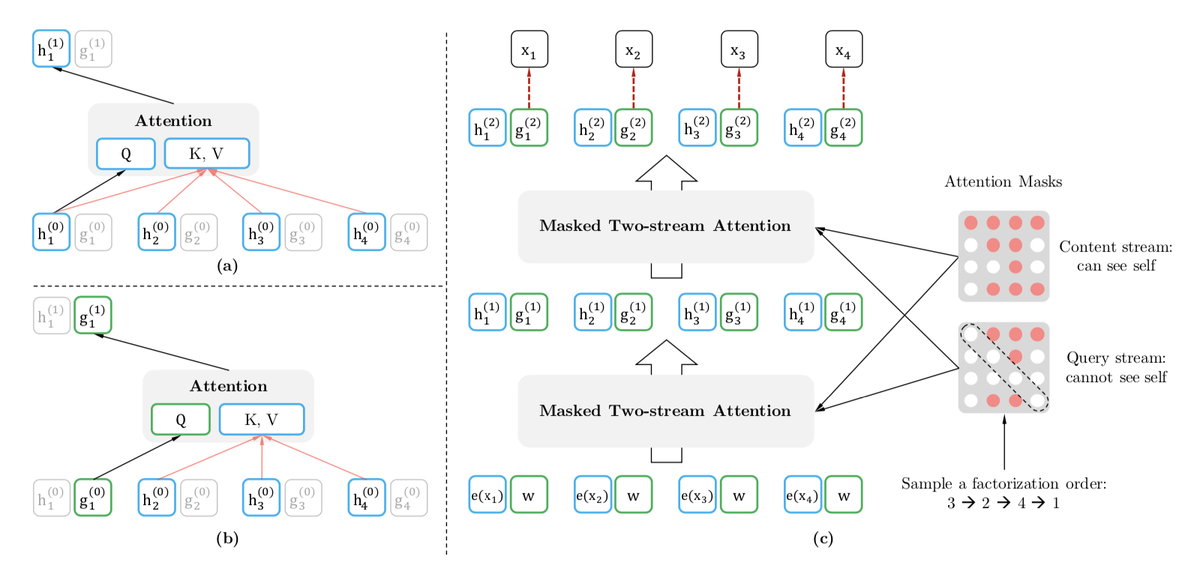
在最后softmax的时候我们把所有的g拿来,h就可以舍掉了: