宏观理解
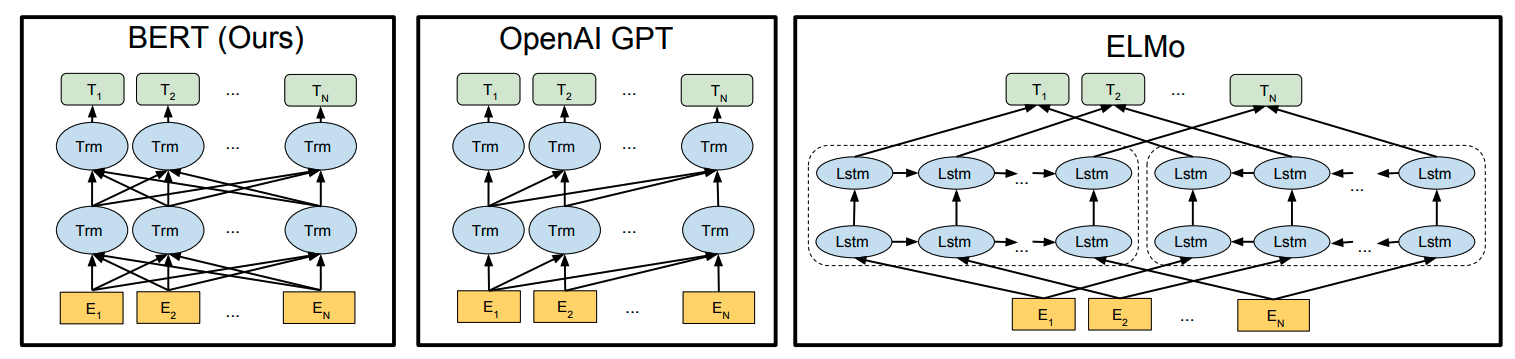
Transformer被人们发明之后几乎是完虐其他的模型,但是问题是如果直接把Transformer应用到众多的NLP领域中,效果不是理想的那么好。此时就有人想那我们可不可以把ELMo用Transformer来架构?
ELMo可以说是通过语言模型来生成单词的词嵌入,用了双向的LSTM,最后再把两个方向上的值拼接起来。后来OpenAI GPT就使用了transformer来替换LSTM。
这里的Trm都是用的Masked self attention。GPT的训练目标是语言模型,也就是给定前n-1个词来预测第n个词,所以这个目标也就决定了GPT是一种单向模型。后来Google团队就打算做一些改进, 丢弃mask,使用Fully self attention,并且是双向的。主旨也是让transformer做一个预训练模型来初始化下游任务中的参数。
微观分析
Bert除了对模型结构的改造之外,还提出了两个训练目标。一个是Masked language model,一个是Next sentence prediction。下面会分别介绍。
我们先来看一下Bert模型的输入格式:
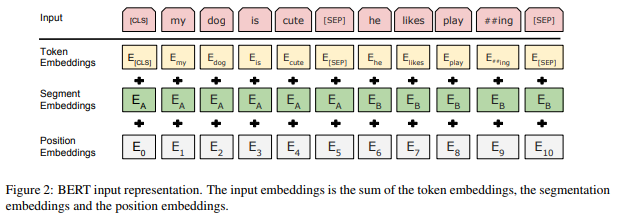
Bert的输入是由两句话组合在一起的,中间用[sep]分割。目的就是因为他们的训练目标其中一个是Next sentence prediction。相比于Transformer,Bert还多了一步就是segment embeddings,目的也是为了区分 两个句子,标注哪个词是属于哪个句子的,在训练的时候是随机初始化的。
Masked language model
之前的语言模型都是用前面的词预测后面的词。Bert在想,能不能让两边的词来预测中间的词呢?但是我们怎么保证在self attention中,模型不只是去把正确的答案复制过来? 我们可以随机把15%的词给扣掉,让模型来预测对应位置的词。但是还有一个问题是[mask]这个标示只是在pre training中会见到,我们在下游任务中不可能再去把我们的预料做一个mask毫无意义。那么这样就会产生 一个pre training和fine tuning之间的gap,这个gap是会影响性能的,那么怎么解决这个问题呢?
我们依然会选出15%的词,但是这些词我们不会全部标记为[mask],而是这15%的80%我们才去用[mask]替代,还有10%我们在词表中随机找一些词来替代,最后10%我们不做任何改变。那如果不使用这样的机制会带来什么坏处呢?
- 如果只使用mask,那么模型就会默认我只要学习好mask的位置应该是什么词就够了,不是mask的词我不需要放精力去管。我们当然不希望这样。
- 如果只使用mask和随机替代,那么模型就会知道这些词肯定都是错误的!我们当然也不希望模型这样认为。
- 如果只使用mask和不做任何改变,那么模型会一定程度上偏向于认为,只要我copy了原本位置上的词,就应该是正确答案。
所以目前这三种方式缺一不可。在训练的时候我们只给这15%的词后加loss来让模型进行学习。
Next sentence prediction
目的是预测输入的两个句子可不可以连起来,或者说两个句子是不是来自于同一篇文本。所以在训练的时候我们给一些句子随机找一个干扰项。
subword
subword是bert使用的一个预处理方法,目的是防止有一些词会超出词表的范围out of vocabulary。做法是我们在编码的时候把一个词给分开,例如subword = sub + word,分别做词嵌入。 例如在上面的输入样例图中的play和##ing。##是在实战中用来表示这个词是和前面的词连在一起的。
常见的算法有
- Byte Pair Encoding(BPE)
- WordPiece
- Unigram Language Model