宏观理解
Transformer是当今nlp领域最伟大的发明了,几乎成了如今自然语言处理的默认模型和代名词。后来的bert系列, GPT系列等都是依赖于transformer的架构拼接而成的。算得上是nlp领域的一次里程碑了。 transformer的主旨在抛弃RNN,只用attention可以让模型更加有效率也更容易被拓展 - attention is all you need。
微观分析
transformer也是沿用了encoder - decoder的架构:
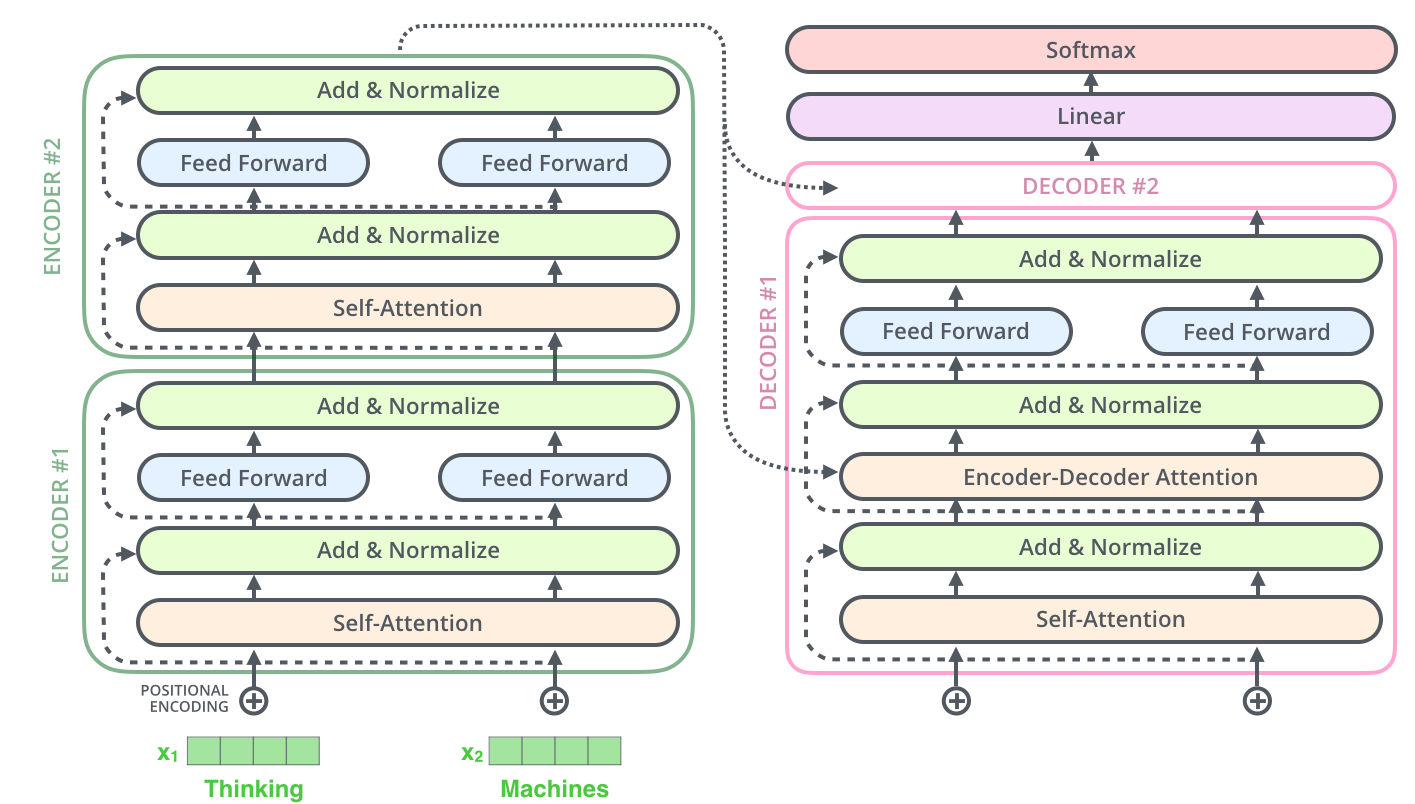
我们可以发现整个结构新颖的地方就是一个叫self attention的block,这就是大佬们推出这个模型的关键点,搞明白了self attention也就搞明白了transformer。 但是在self attention中还隐藏着两个重要的trick,一个是multi-head,一个是mask。人们叫做multi-head self attention和masked multi-head self attention。 接下来分别看一看。
self attention
首先我们把所有的输入向量给到模型,比如图中的x1和x2,那么对应的也就有了两个输出y1和y2。像之前说的attention一样,我们的每一个y,是对所有x的一个加权平均。可以表示为
。但是其中和attention不一样的是,我们此时的权重w不再是decoder的隐向量和每个input隐向量点乘了,而是所有的x之间互相做点乘
再过一个softmax得到
。
例如此时我们要计算y2,也就是要用x2分别和x1、x2自己、x3、x4点乘,得到了每个w权重。再把4个w值过一个softmax映射成概率分布。假设我们得到了0.1、0.5、0.2、0.2之后,做一个加权平均
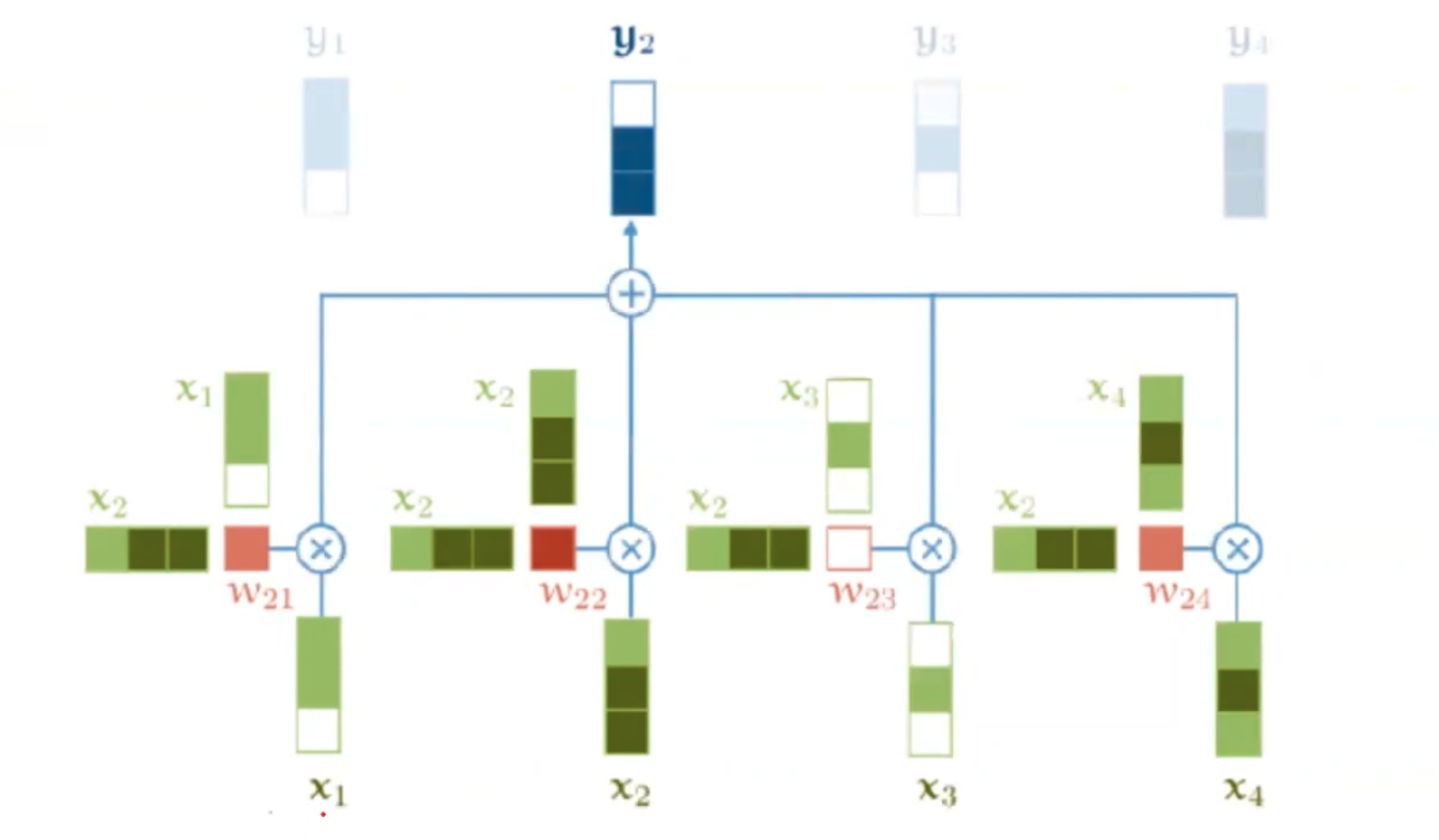
这样的一个过程就叫做self attention。
self attention可以告诉我们如果x1和x2的词很相似,那么他们的权重w就会很大。并且整个过程我们不需要额外的参数,这样就会让我们的self attention不容易过拟合。但是有好也就有坏,通过这种方式,我们可以发现如果我们把x1和x2换一个位置,那么我们得到的y2是一样的。这也就代表了self attention无法考虑到输入序列的位置信息。为了解决这个问题,我们就要引入一个positional embedding位置编码的机制。
Positional embedding
我们需要的只是每个单词的位置信息,那么我们可以生成一个位置向量,让它和输入input的维度相同,然后把他们两个相加即可。我们的位置向量按照sin和cos函数计算:
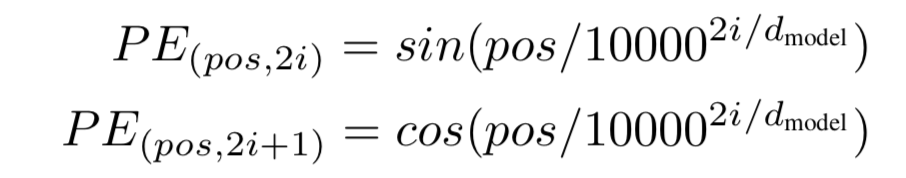
其中pos是位置编号,比如在计算第二个词的时候,pos就是2。i是index over dimensions,使得embedding有维度d个。
为了概括之前的attention和现在的self attention机制,我们使用一种共通的命名(query,key,value)对。刚开始看这些东西的时候一定会很混乱,网上各种介绍也都不是很通俗,我来尝试解释一下:
我们的每一个输入x在做attention的过程中分别会扮演三种角色,分别叫做query、key和value:
- query:我要和其他的所有向量相乘来计算权重的时候,我的角色叫做query。比如在attention中的decoder隐向量,在self attention上个例子中的x2自己。
- key:当我需要配合和query向量计算权值的时候,我的角色叫做key。比如在上例中的x1、x2、x3、x4都需要配合x2生成权值,他们此时就叫做key向量。
- value:当有了权值之后,我需要和权值做一个加权平均来计算y值。比如在self attention中的所有x。
所以我们可以看出来,当我们在计算y2的时候,需要用x2作为query和x1、x2、x3、x4作为key点乘,之后我们再通过点乘的结果权重分别乘以x1、x2、x3、x4作为value的加权平均得到y2。x2同时扮演了三个角色。
随后人们发现,如果我们可以让x2在同一个时刻的不同角色有一个更清晰的认知,那么训练的效果会更好。比如我们给设定三个可训练的参数矩阵,当x2作为query的时候我需要x2乘以Wq。当x2作为key的时候我需要x2乘以Wk,当x2作为value的时候我需要x2乘以Wv。
所以在self attention中,我们可以对每一个input x都生成3个值,分别对应该输入x作为不同角色的时候的输入。所以我们就会有3个序列,分别为query序列、key序列和value序列,这样我们的self attention的计算过程就变成了这样:
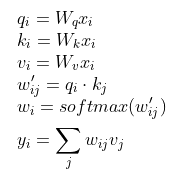
那么我们上一个例子中的y2计算过程可以这样表示
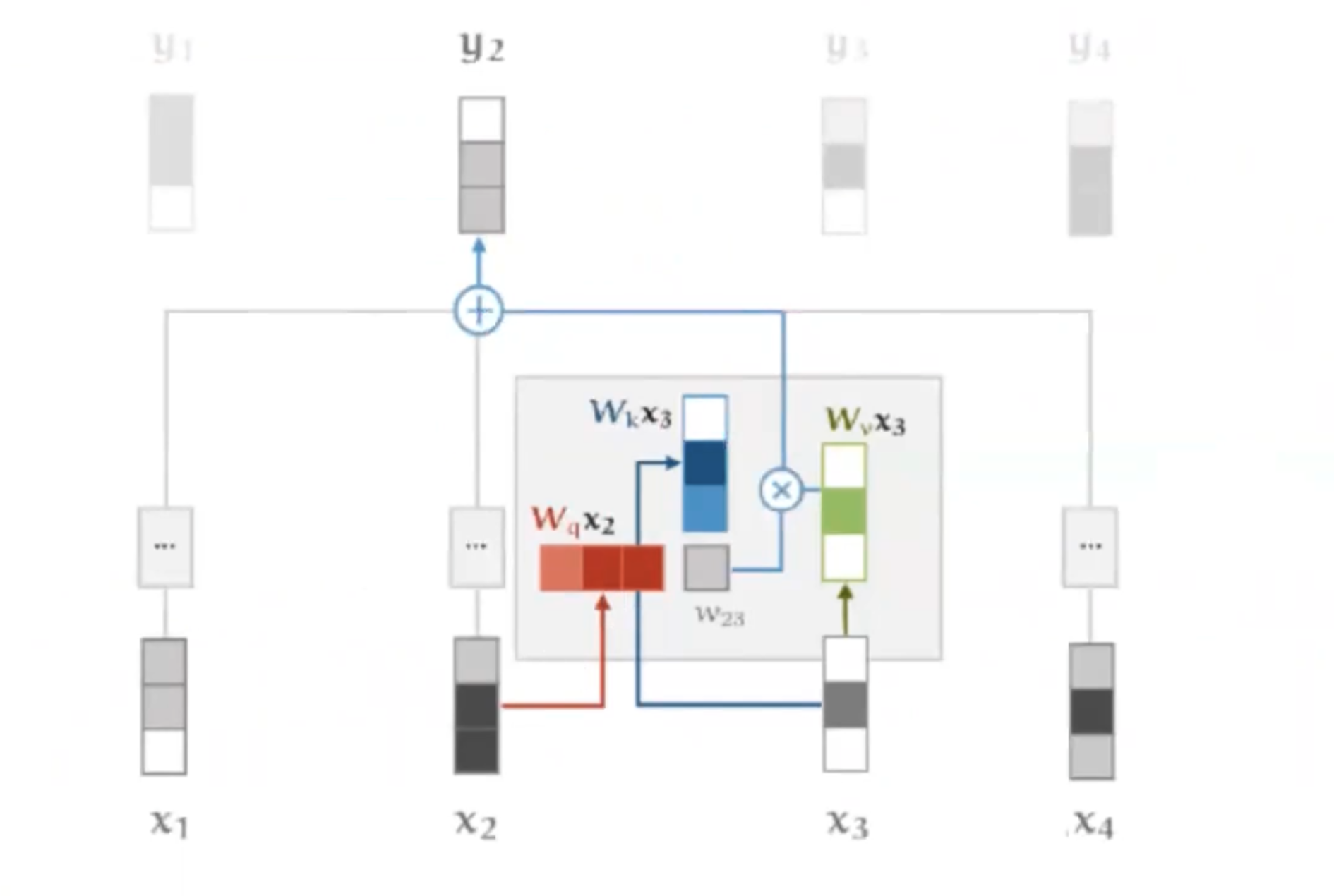
但是随后还发现了一个问题,就是我们在求softmax的时候,如果输入很大的话,那么经过softmax输出就会更加被放大。所以通常来说我们需要一个trick就是在求w权重的时候我们做一个归一化,除以,dk就是模型中隐向量的长度。
multi-head attention
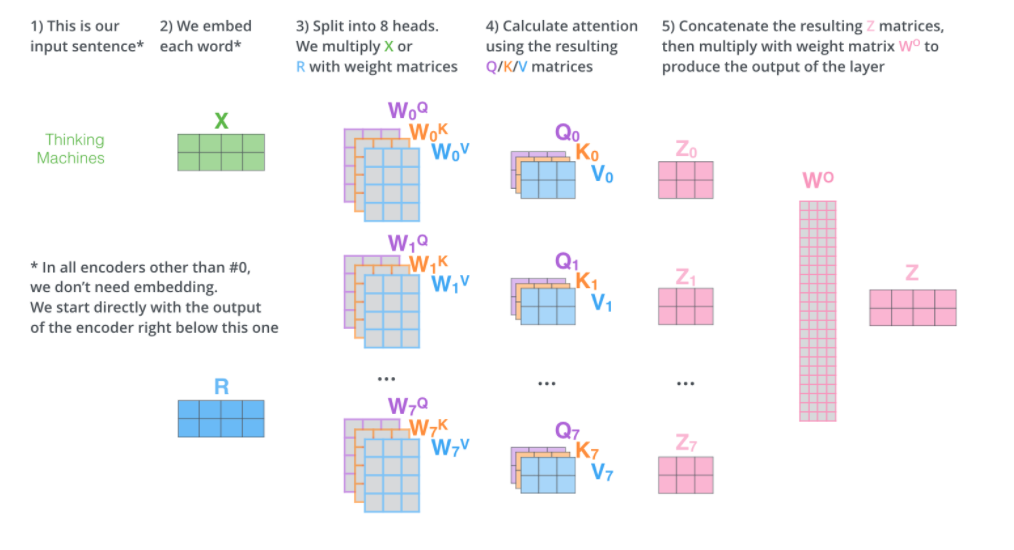
在说完self attention的过程之后,multi-head就容易很多了。论文中说为了学习到不同方面的信息,所以他们把一个input平均分成了几份来分别做self attention。但是随后也有一些论文研究说分成多头之后,这些头并不会出关注不同的东西。所以究竟multi-head的原理是什么,我相信没几个人能说得清楚。深度学习的可解释性还是需要人们去研究的。
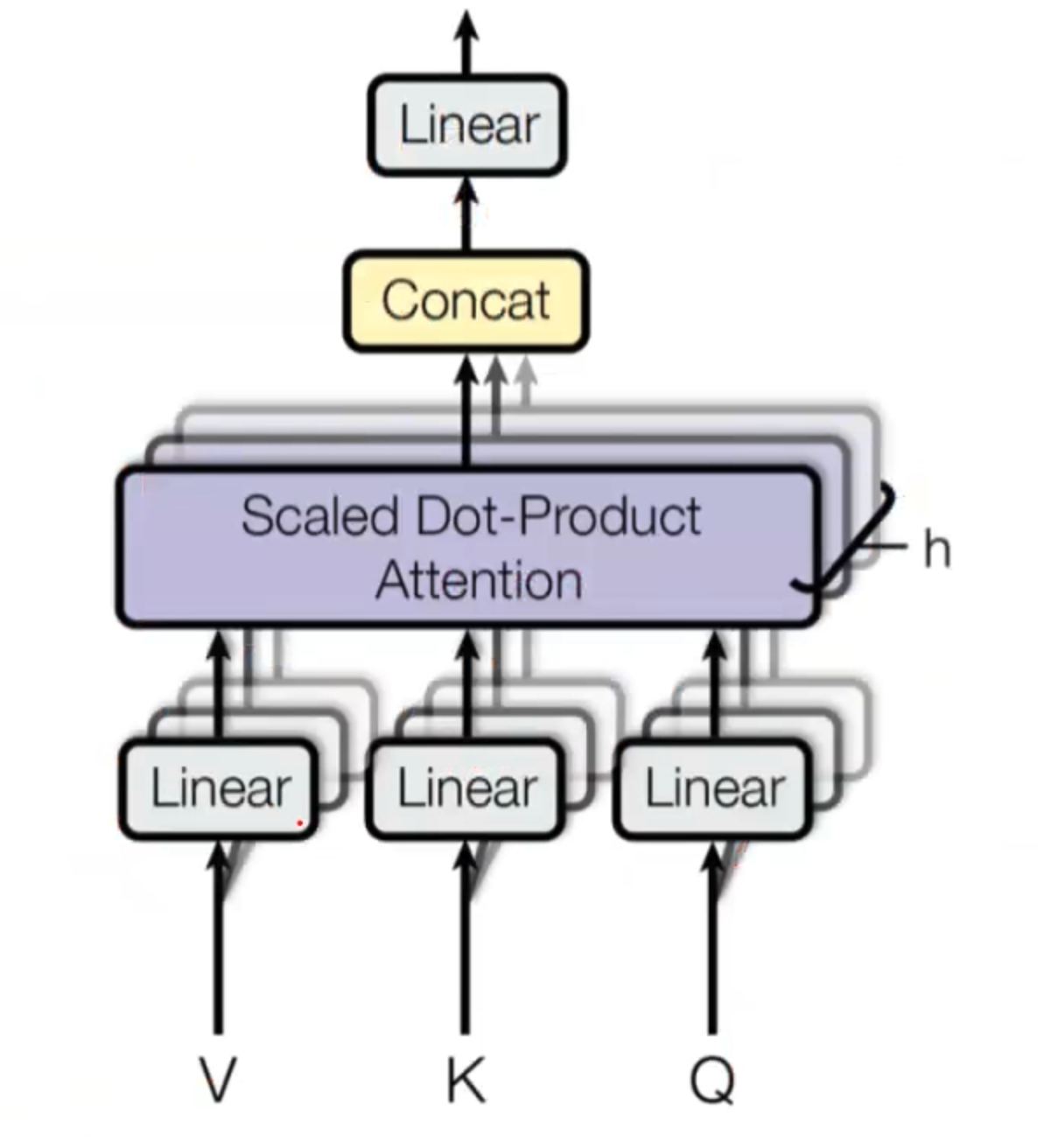
我们在输入的时候每个x分成若干段,对所有x的每一段都分别做一个self attention,最后再把所有的结果concat起来,喂给输出。
Residual operation
我们拿到输出之后,要先做一个残差操作,把self attention得出的结果和原始input相加喂给norm layer。为的是避免梯度爆炸或者消失,这是深度网络中常见的一个trick。
norm layer
拿到残差输出之后,下一步要通过一个norm layer。注意这里我们仍然有|input length|个输入。我们要对每一个输入做一个归一化。所以我们首先要求出每一个输入向量的均值和方差,然后对该向量里面的每一个数做一个转化,其中ε是我们为了防止分母为0加的一个平滑项,γ和β是两个可训练的参数,是每个layer共享的,也就是在这一层中所有的输入的γ和β是共享的。
Feed forward layer
然后再把每个输出给到一个单隐含层的神经网络,就是有w和b两个训练参数再过一个relu激活函数,跟单层神经网络是一样的。
总结一下,我们说的transformer block就是这样的一个过程:
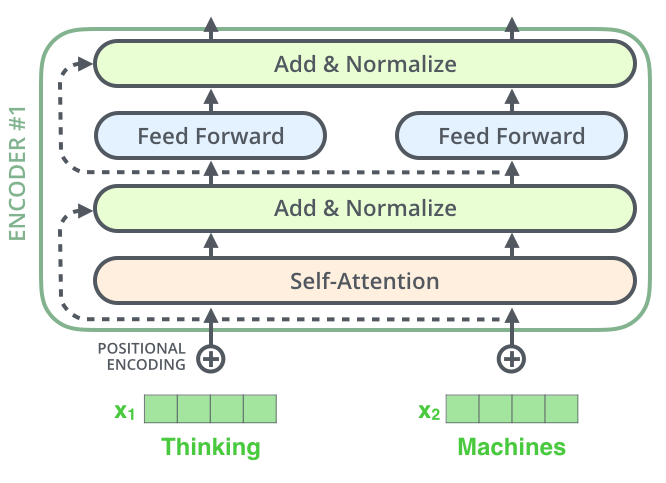
- 得到输入和对应的位置编码,相加
- 喂到multi-head self attention中,拿到输出
- 残差计算,把attention中的输出和原始input相加
- 喂给norm layer,对每一个vector分别归一化
- 喂给一个单层神经网络,通过一个relu激活函数
- 残差计算,把网络中的输出和norm layer后的输出相加
- 喂给第二个norm layer得到归一化后的输出
- 如果有下一层的transformer block,作为输入传入下一层循环到step 1;如果没有,输出结果。
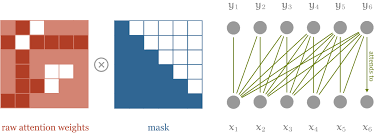
Attention mask
我们已经有了完整的一个transformer block了。下面就可以训练了。如果是类似于情感分类的任务我们不需要做其他的事情,但是如果我们做的任务类似于text generation,还需要使用一个操作叫attention mask。
假设我们在学习hello这个单词,我们会把h e l l o一起喂给模型,这样就会有一个问题,在计算loss之后反向传播时h可以看到它后面的字母是e,l也可以看到它后面是o。这样学习的话模型就会偷懒,它会知道我要的答案其实就是下一个输入,我已经看到了。所以为了避免模型作弊,我们要在attention的结果之后加一个mask来强制e只能看到h,l只能看到前面的he。
以上是我们encoder的全部过程,对于transformer block的讲解已经完毕了,但是最后还是提一下decoder的过程。它当然也是使用的transformer block。
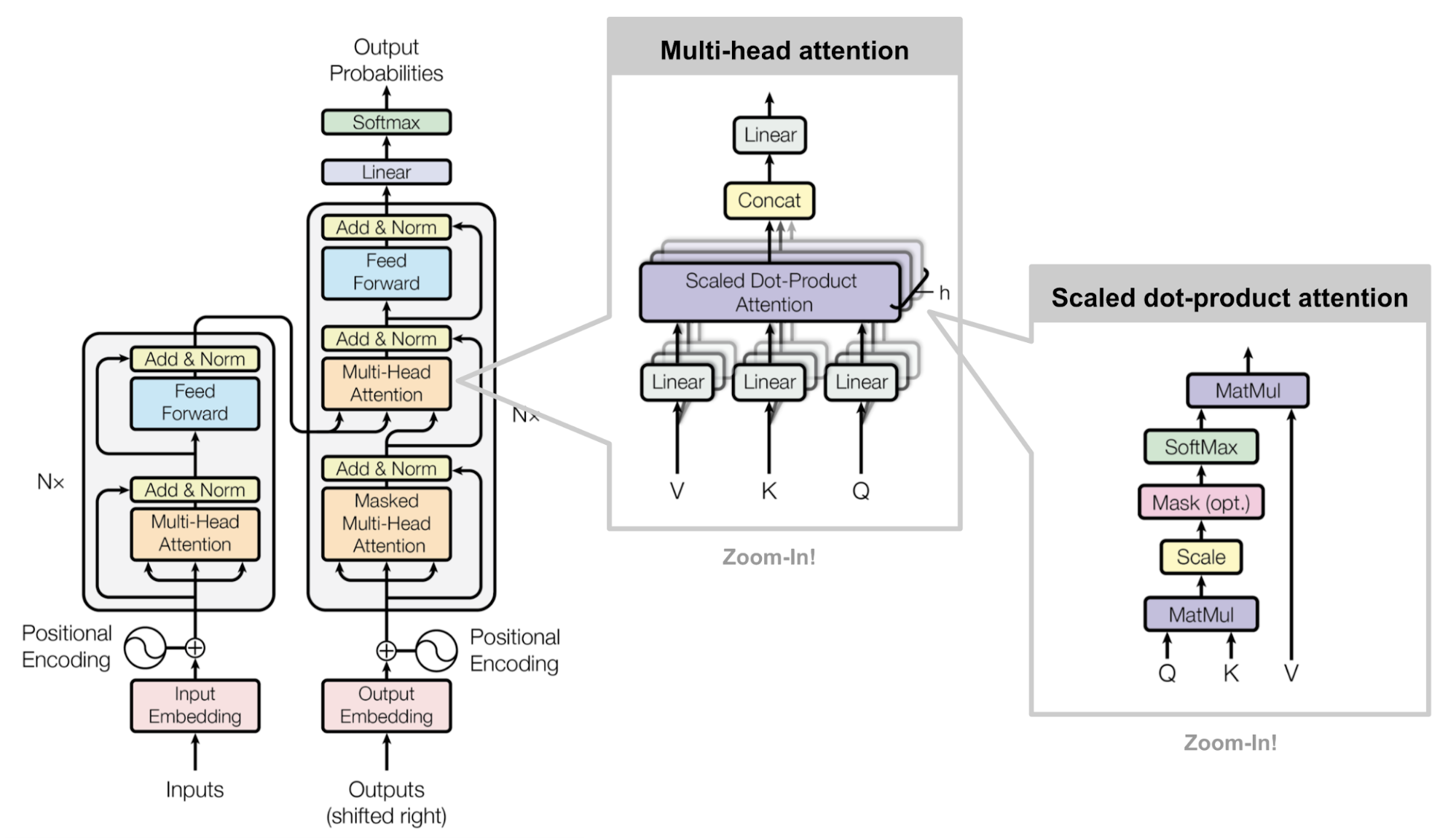
我们得到encoder的输出之后,因为我们是一个auto regressive model,所以我们Y1到Yn-1和x给到decoder。就是图中decoder的输入。照常我们做一个mask multi-head attention和norm layer,此时的输出是n-1个。随后我们需要把norm layer的输出作为query,把原本encoder的输出作为key和value进行一个attention计算。最后过一个softmax得到输出概率即可。
这里encoder和decoder一般叠加6或者12层,主要就看自己是不是土豪了。