宏观理解
在RNN或者在seq2seq模型中,有一个中间向量context来描述encoding的所有含义,然后再通过decoding解码。这样会产生两个问题,我们叫bottleneck problem:
- 中间向量的生成如果一旦有问题,那么整个后面的解码过程都完蛋了。
- 无论输入是10个词还是100个词,我们没办法保证context vector都可以学到一个很好的描述。
那么我们能不能按照人类的思维模式来改进?比如当我们翻译today这个词的时候,我们不会去过度关注后面的所有词,把更多的精力放在today这个词就好 – attention is all we need
微观分析
网上找到这个图可以很好的展示我们要做的事情:
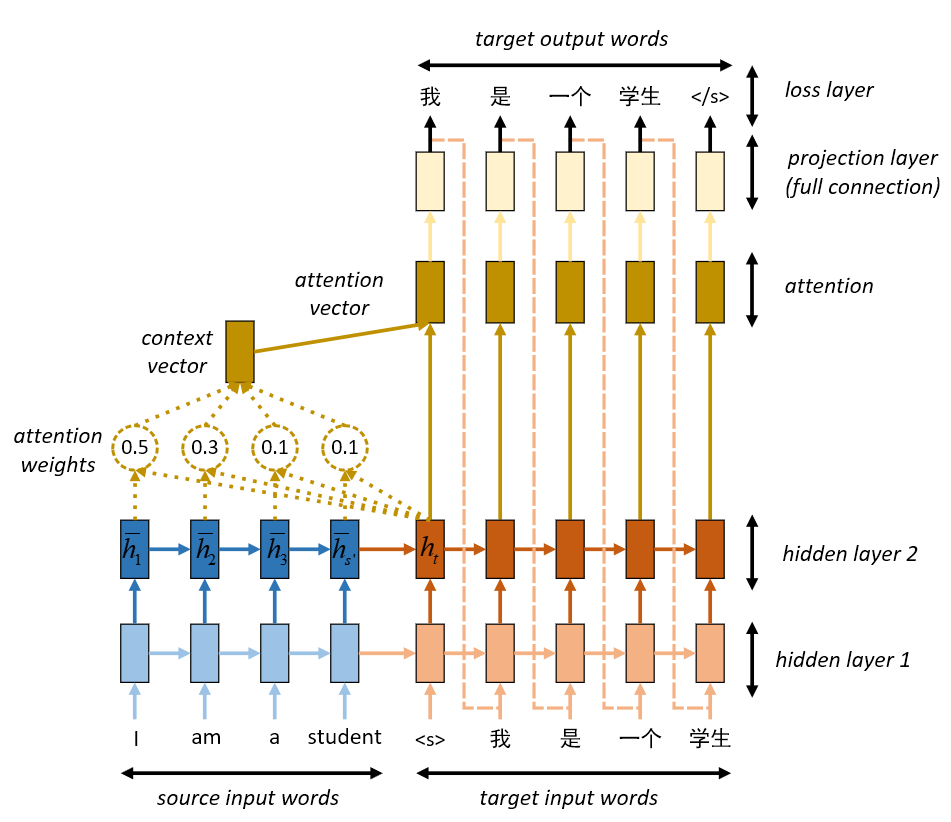
从