宏观理解
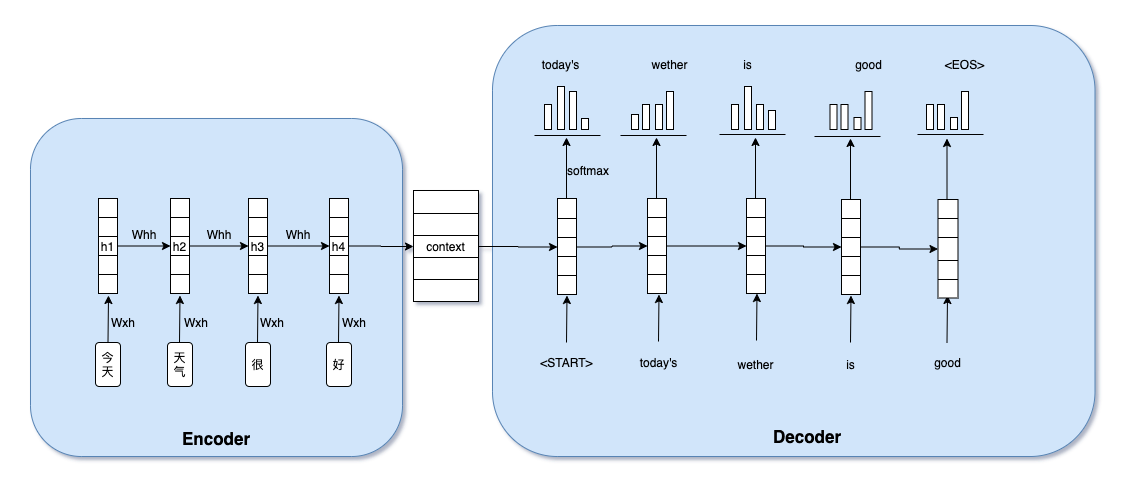
Seq2Seq由前后两个RNN拼接而成,一个叫encoder一个叫decoder。encoder负责把输入输进模型之后生成一个context向量,包含所有文本信息。decoder负责把context向量解码成我们想要的结果。 好处是它解决了输入定长的问题,我们不需要再纠结于输入和输出的长度限定,最好的例子就是机器翻译,中文的token个数可未必和翻译出来的英文token个数一致。
微观分析
例如我们下面的这个例子中,decoder根据context信息经过一个softmax生成了第一个结果today‘s,然后再把today‘s和hidden weight喂给时刻2的decoder,经过softmax生成了weather。但是现在问题来了,我们每次经过softmax的时候都是找到概率最大的那个,假如有一种情况是在时刻2经过softmax后is的概率比weather高一点点,那么模型就会认定输出为is。这种情况显然不是我们想要的。
这种算法叫Greedy decoding,它每次都贪心的选取当前时刻最优的选择。但是我们怎么去避免这种情况发送呢?
Exhaustic Search
最容易想到的就是暴力解决,也就是每次在softmax之后我们选择全部。假设在时刻1的时候有10种选择,那么我们再把每种选择都预测下一个再生成一共100个选择,。。。这样继续下去复杂度就是可选择个数v的指数级。虽然这样可以拿到全局最优解,但是太过于复杂笨重。
随后人们就想有没有这两种方法的折中呢?我们不光考虑一个,也不要去考虑所有,那么我们可以每次考虑k个。
Beam Search
我们每次在生成比如10个候选的时候,我们先把每个概率加一个log,然后选出k=5个概率最大的。然后我们再把这5个给到下一个时刻2,这5个一共会生成25个,但是我们同样的取完log再选出迄今为止(注意迄今为止指的是要用当前的概率加上时刻1的概率的总和,不单单使用当前轮的概率)最大概率的5个。我们把这个过程画成图就是这样的:

直到最后遇到了一个end指示符并且概率是最大的时候才会停下来。
但是这样就有了另一个问题,如果有一条路径很早的就遇到了end指示符,那么很大可能也代表它的概率是最大的。因为我们取完log之后概率会变成负数,越早停止相加的数会越大。所以这就造成了模型总是偏向于选取那些很短的路径。
解决方式也很简单,就是我们可以加一个normalization项,比如在每轮的概率下除以一个当前轮次。比如我们在时刻2的时候有5个候选,这5个我们都除以2。时刻3的时候我们都除以3,。。。依此类推。
还有一个小trick,如果我们不想让某些单词出现在k候选里面,我们可以设置beam search在遇到这些词的时候就跳过。这时候我们整个算法的复杂度就变成了k的平方。