宏观理解
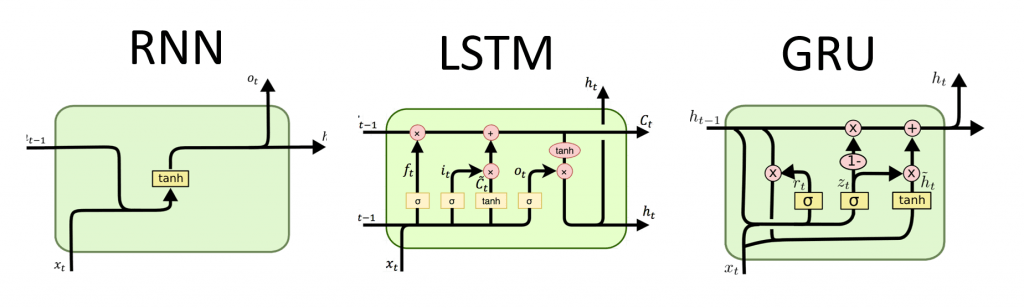
LSTM是长短期记忆的简称,用于处理有时序信息的文本。它的诞生旨在解决RNN的梯度爆炸和梯度消失问题。在RNN的隐含层中由于随着句子的长度变长,梯度会产生各种问题, 例如如果梯度小于1时,n多个隐含层连乘会导致趋向于0;大于1是会导致趋向于正无穷。所以在RNN中解决这个问题的途径比如说我们随机的drop out掉某些隐含层的值,这样在 梯度会大大减缓爆炸或者消失的问题。但是有人就想,我们可不可以让模型自己学出来,该在哪里drop out掉哪些隐含层呢?LSTM的诞生就解决了这个问题。
可以看出,在从RNN到LSTM的变化,其实只是把原来的一个去线性层复杂化了一点,下面我们会分析一下到底复杂在了哪里。
微观分析
我们看到下面是一个LSTM的cell
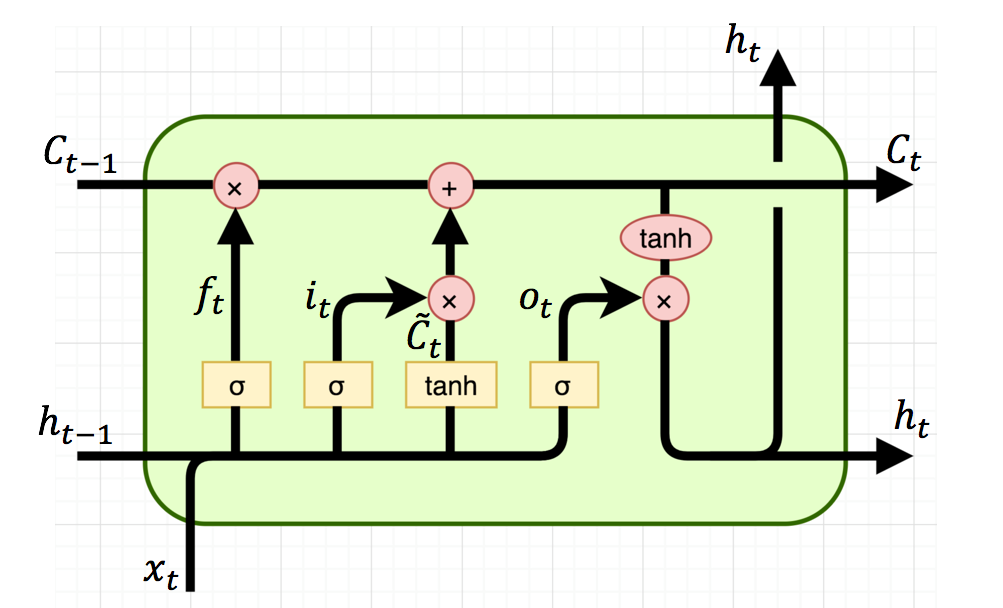
看起来很复杂但是我们一点一点拆开来看。
我要去遗忘什么?
首先我们看一下forget gate layer遗忘门,他的目的是来控制“我要去遗忘什么?”
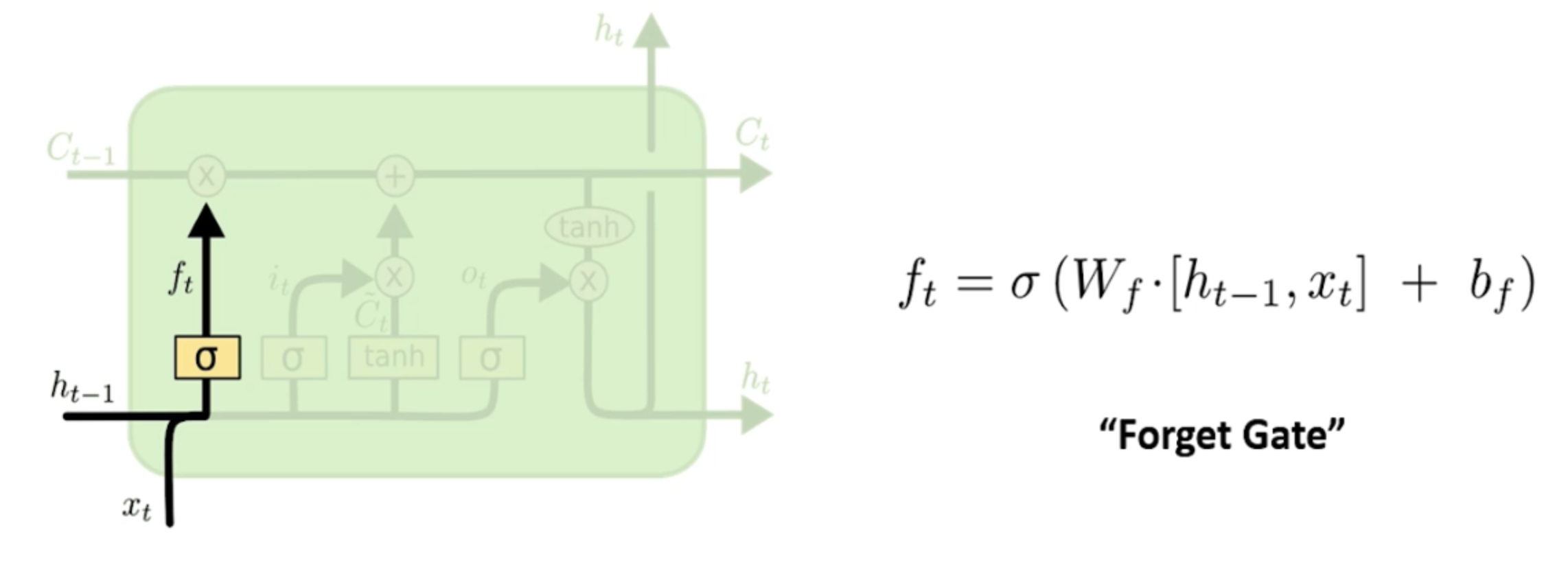
每一个时刻的input xt要和上一层传来的隐含层做一个sigmoid,我们知道sigmoid的结果无非是0/1,那么我们就可以把0当成是“遗忘”,把1当成是“记住”。所以在 模型学习的过程中,如果此刻的结果变成了f_t = 0,那么也就意味着再和上一层进来了C点乘,那也还是0。
我要写入什么?
接下来我们看input gate layer输入门,他的目的是来控制“我要去写入什么?”
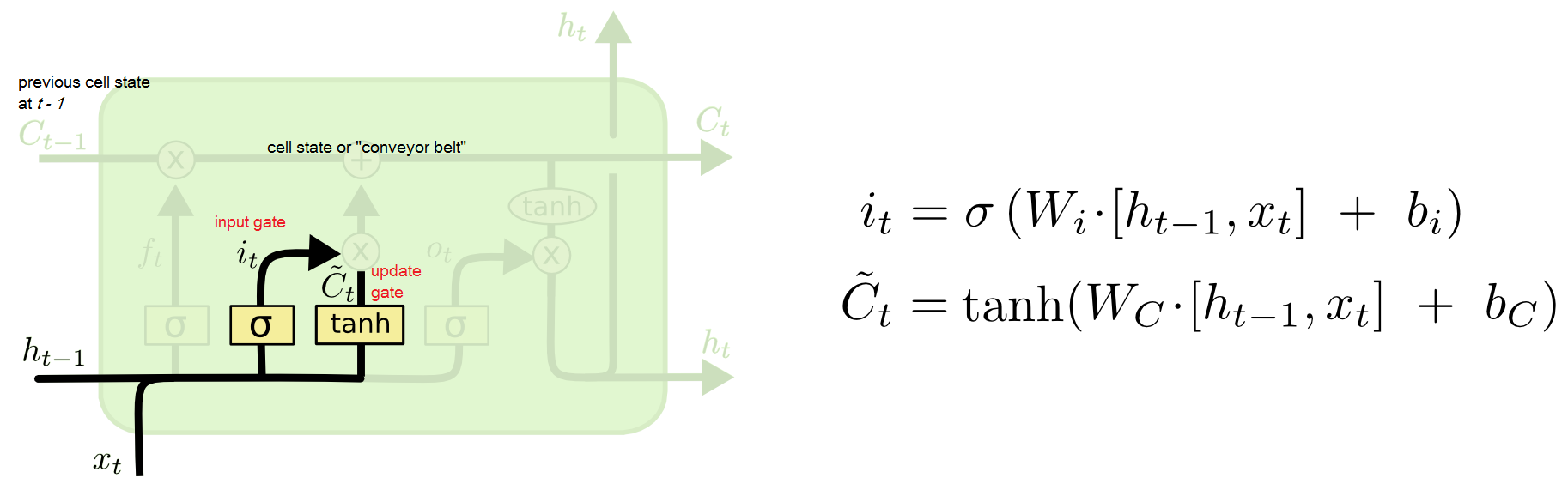
和遗忘门相同的原理,我们用i来作为要不要写入的判断,然后我们新引入一个C值来控制我们要写的东西的内容。
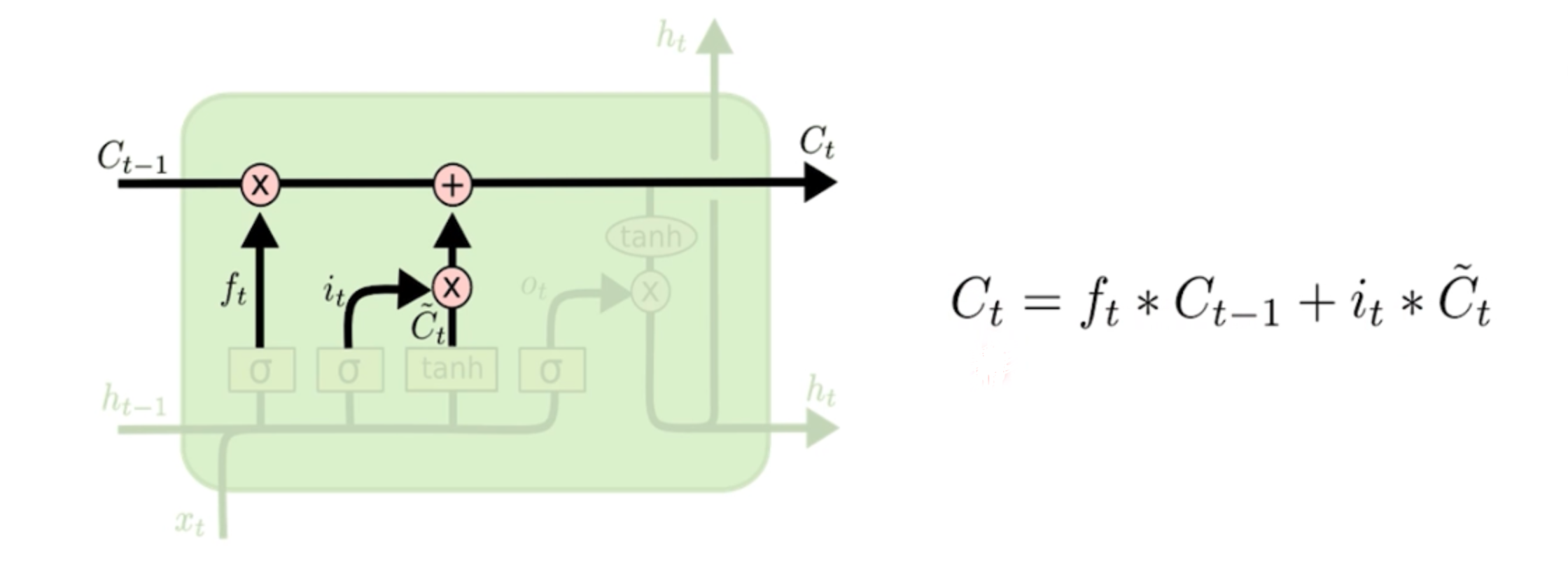
遗忘什么并且写入什么?
接下来我们有了之前的遗忘的内容和要写入的内容,我们就可以做一个整合,叫做long term memory长久记忆区,用来整合“遗忘什么并且写入什么?”
从长久记忆区拿出什么作为输出?
最后我们有一个output gate输出门,用来掌控“从长久记忆区拿出什么作为输出?”
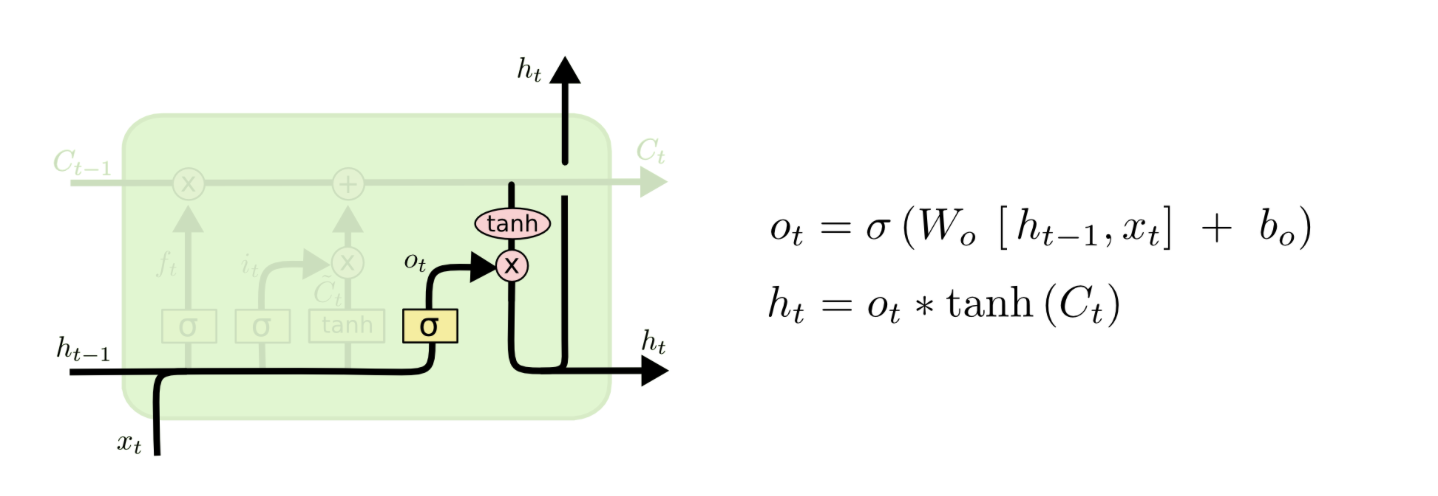
像前面的遗忘门和输入门一样,我们先要一个控制器来判断我们要不要拿出来一些记忆,所以我们的o用来判断拿还是不拿。然后我们要输出的内容肯定是在记忆区C的里面,所以 我们用tanh过一下记忆区来找一下我们应该输出哪些记忆。
一整个隐含层的计算流程
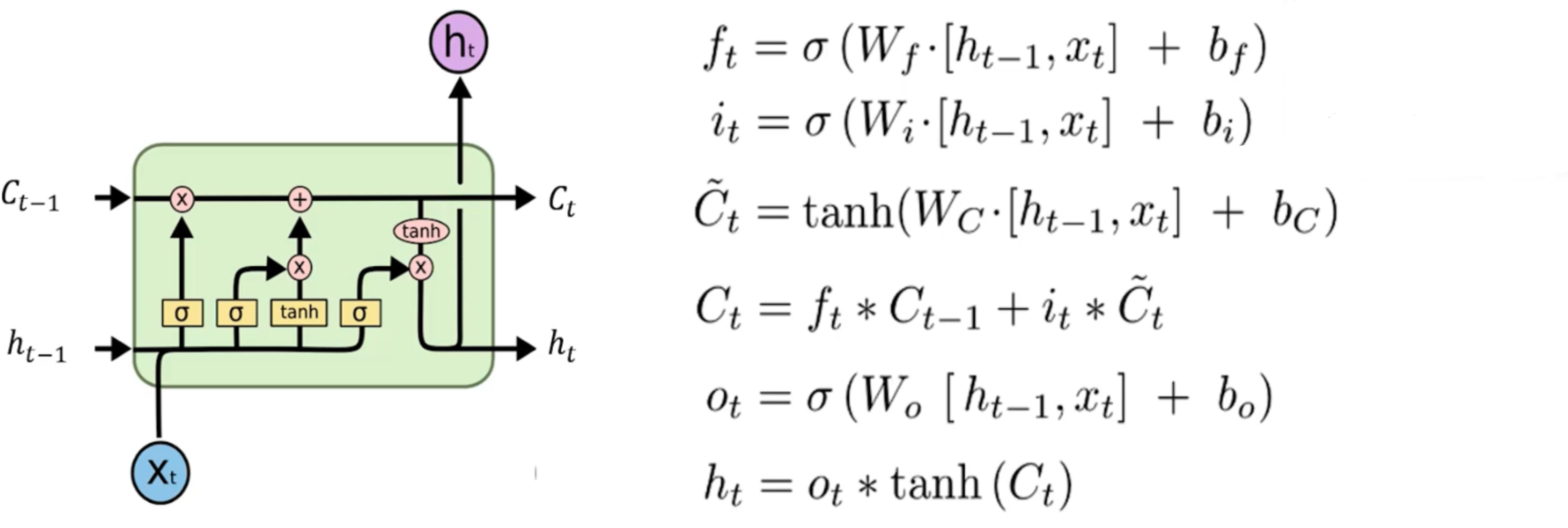
多种变体
很多LSTM的应用并不会使用最基本的结构,会在基础上加一些变体。我们一起来看另外的3种变体:
Peephole connections
唯一的区别就是在三种门的计算中,加入了之前的长久记忆。
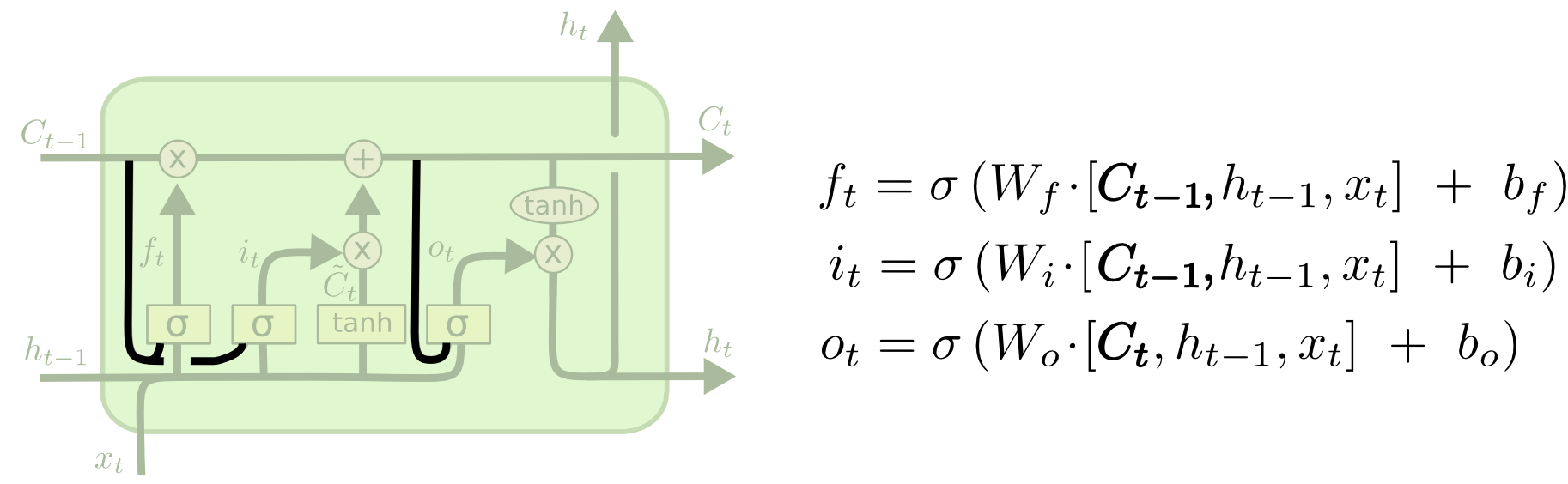
Coupled forget and input gates
唯一的区别在于原本的LSTM的遗忘门和输入门是独立存在的个体,互不影响。现在我们想让他们一起来做决定。
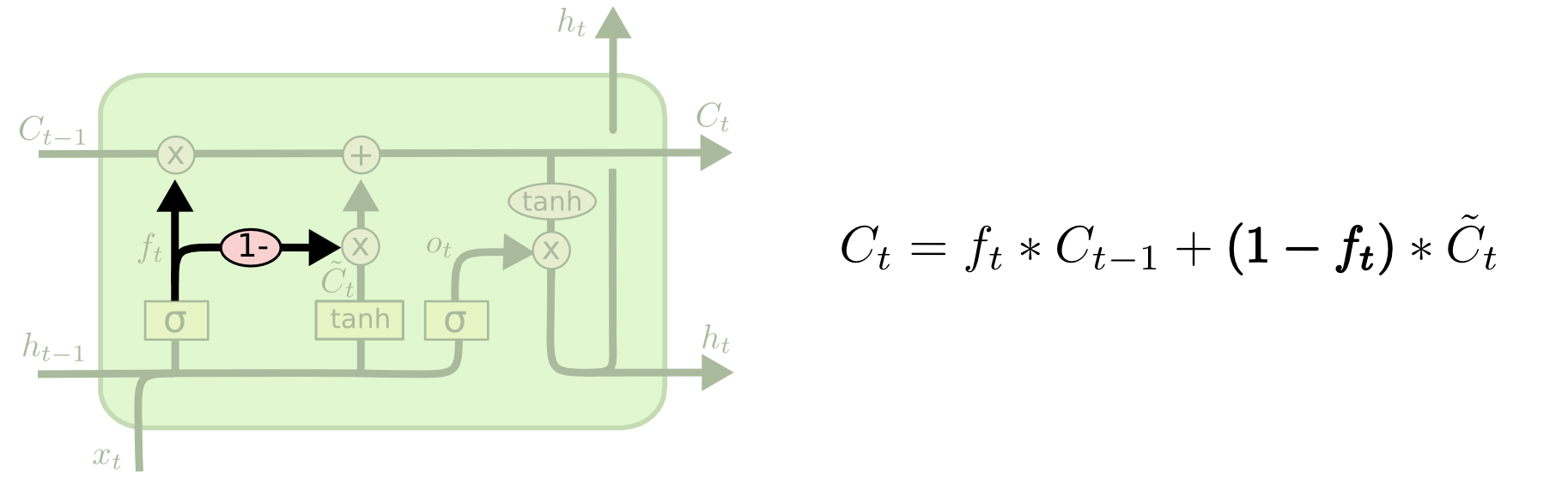
Gated Recurrent Unit
也算是大名鼎鼎的LSTM变体GRU了,为了省略LSTM中臃肿的参数,提出了一种只包含两个门的变种,把遗忘门和输入门结合为一个“更新门 update gate”利用了更少的参数计算,但是效果有时未必有LSTM好。

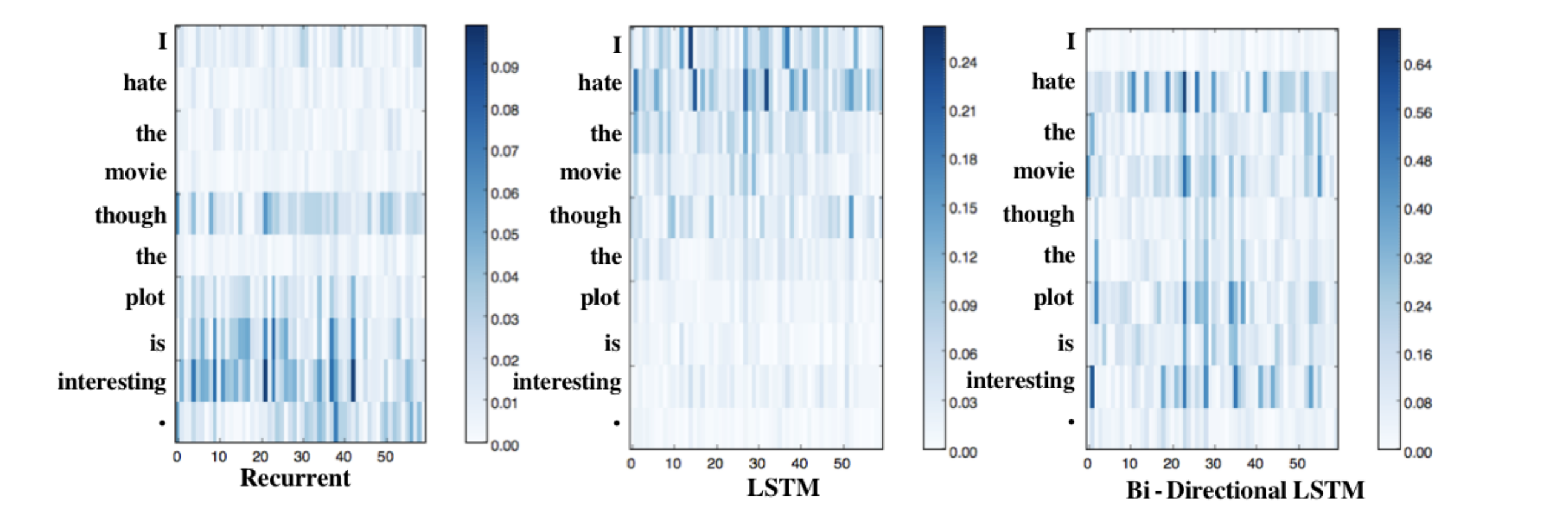
双向LSTM
双向的LSTM我们可以认为他就是两个单向的LSTM组合在一起。
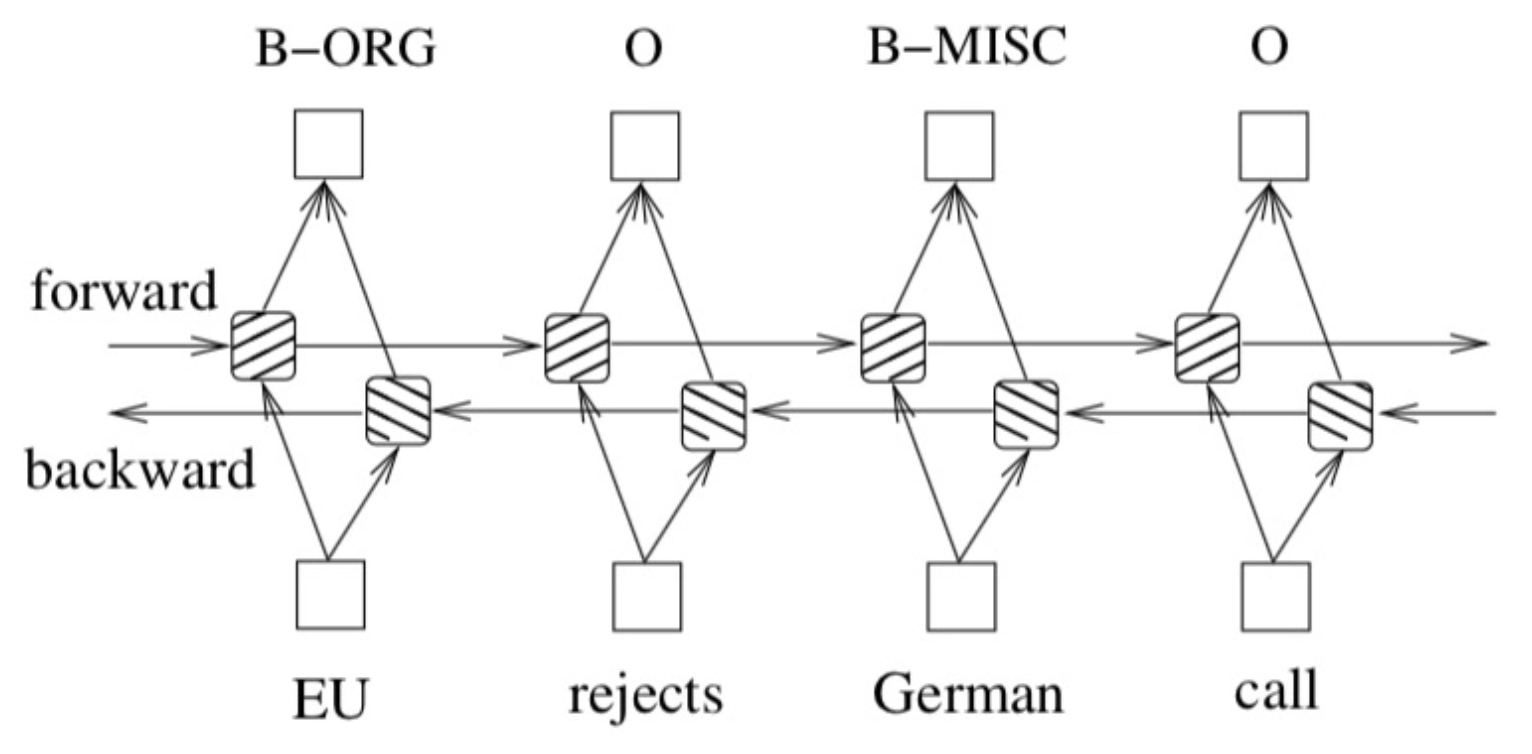
有时候我们需要从上下文来考虑问题,所有从一句话的前到后和后到前我们都想要考虑到。 下面的这个图可视化了三种模型对句子中每个词学习到的重要程度,可以发现如果我们用单向的LSTM它可以把前面的单词学习的很好,但是越往后学习能力越不够,所以这个时候如果还有另一个LSTM从句尾往前学习一遍就可以弥补这个不足。