宏观理解
AdaBoost是 “Adaptive Boosting”的缩写,它是集成学习中boosting方法的一种实现,目的就是把很多的弱学习器集合起来变成一个强大的学习器。AdaBoost主要任务是分类问题,当然也可以做回归但是一般不会选择AdaBoost。和之前见过的GBDT一样,他们都是迭代算法,但不同的是GBDT迭代的是残差residual,而AdaBoost迭代的是权重。所以一句话形容AdaBoost的训练就是更新每个模型的权重和数据点的权重的过程。
微观分析
既然迭代的是权重,就是说每轮过后模型的权重都会稍微变化。在AdaBoost中模型和数据点都具有权重。和GBDT一样是一个加法模型,公式如下:
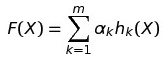
α是每个基模型的权重,h就是每个具有不同参数和权重的基模型。我们要做的就是训练出这m个基模型后把他们的结果按照权重相加起来就是最后的结果了。
对于模型的权重,那肯定是如果这个基模型的分类效果好,正确率高,那么属于它的权重就要高一些。就好比领导人的威望一样。但是数据点的更新则相反,那些越容易被分类错误的数据点的权重越高。就好比班里调皮的同学总是能得到班主任更多的关注一样。
所以整体AdaBoost的过程很简单:
初始化样本权重 = 1 / N 对每个基模型拟合数据并作出预测 更新模型的权重 更新数据点的权重 伪代码如下:

下面分步说一下伪代码的过程:
- 我们用Dk(i)来表示第i个样本在第k个基学习器学习后的权重
- 我们用αk来表示第k个基学习器的权重
- 初始化所有数据点的权重为1/N
- for loop对所有的基模型,也就是要提升的次数进行循环更新:
- 随机有放回的抽取样本,放到D中
- 用基学习器学习数据集D [标注0]
- 用该学习器作出预测,计算出该模型的weighted error [标注1]
- 使用计算出的weighted error对该学习器的权重进行更新[标注2]
- 对数据集D中的样本权重进行更新[标注3]
[标注0] AdaBoost的基模型在paper中作者的建议是决策树,使用的损失函数是指数损失函数而不是交叉熵:
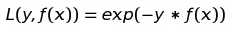
[标注1] 我们用来计算weighted error的公式是:
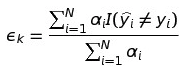
分母为全部数据点的权重和,分子为所有被错判的数据点的权重和。
[标注2] 我们得到了weighted error后在中使用下方公式计算出学习器的更新权重:
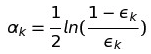
[标注3] 对模型的权重更新完后我们还要更新数据点的权重,使用的公式为:
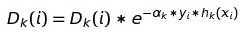
备注:在AdaBoost中我们使用的标签为1/-1而不是0/1(新label = 2 * 原label – 1),原因就是在最后的数据点更新中, 我们可以把y = 1/ -1综合到一个公式来表达。如果y = 0的话那么hk也就有可能等于0,那么e的幂最后变成了1,权重将不会再更新。还有一点值得注意的是,我们在更新模型权重后所有的权重加权有可能不是1.0,还有就是在模型预测的时候有新样本进来最后所有模型预测的概率总和也未必是1.0 。这是可能发生的,因为在更新过程中我们难免会有小数点的计算误差在,所以我们解决这个问题的方法是归一化,也就是除以当前权重的总和。