宏观理解
混淆矩阵是一种评价指标,用来直观的计算某个学习模型的好坏。通过混淆矩阵我们可以计算出各种需要的评价指标。 ROC curve用来可视化比较分类模型的结果,很多时候听到的AUC值也就是ROC curve下的面积,等同于正确率。
微观分析
混淆矩阵一共由n*n个值组成,n是数据中label的个数。在二分类中由0/1构成(标记可能为yes/no,positive/negative等等根据情况而变):
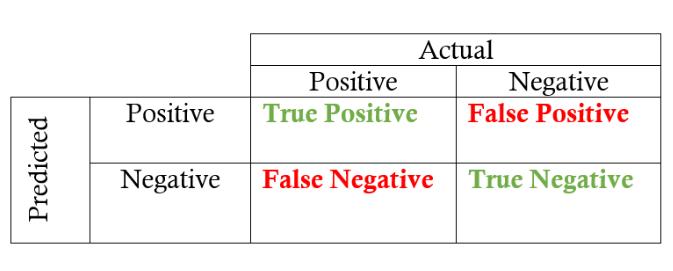
其中我们需要的就是四个数字:
TP (True Positive): 真实值为0,预测值也为0
FN (False Negative): 真实值为0,预测值为1
FP (False Positive): 真实值为1,预测值为0
TN (True Negative): 真实值为0,预测值也为0
其实翻译成人话很好理解,比如TP (True Positive),真实值属于猫的中我预测为猫的是多少个;FP (False Positive)就是真实值不是猫的,但是被我预测成猫的有多少个。
然后根据这四个数值,我们可以推演出一些评价指标的计算公式:
- Precision:代表某一类中,你预测为正的样本中有多少个对了
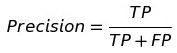
- Recall: 也叫做敏感度(Sensitivity)。代表某一类中,正样本你预测对了多少个。 这个指标有一个典型的应用就是类似于肿瘤预测,如果病人没得病你预测成有病还好,但是如果有病你预测成了没病这是要死人的啊。 所以在这种情况下的学习模型就会把recall作为评价指标,而不再是accuracy什么的。
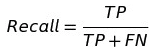
- Specificity: 代表在某一类的负例中,你预测对了多少个。

- Accuracy: 代表所有样本中,你有多少个预测的和真实值是一样的。也就是最常见的正确率。
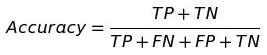
- F1 score: 用于综合考虑Precision和Recall的一种调和平均值,多用在label的种类个数不均衡的情况下。 比如信用卡盗刷预测,可能你10万笔交易中只有100笔是盗刷的,这种标签就及其不平均,如果单单用Accuracy来作为指标, 那么一闭眼全预测成正常交易的准确率也要有99%以上就毫无意义了。
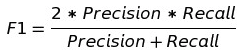
除了以上的一些指标外,还有TPR、FPR 和 TNR这三种写法:
- TPR:也就是Recall或者Sensitivity,同义。
- FPR:代表在某一类的负例中,你预测错了多少个。
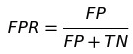
- TNR:也就是Specificity,同义。等同于 1 – FPR 混淆矩阵在多分类的情况下也会变得更复杂,但是原理是一样的,下图代表的也就是当真实值分别为1-6时预测值为1-6的个数。直观看一下就不再赘述了:
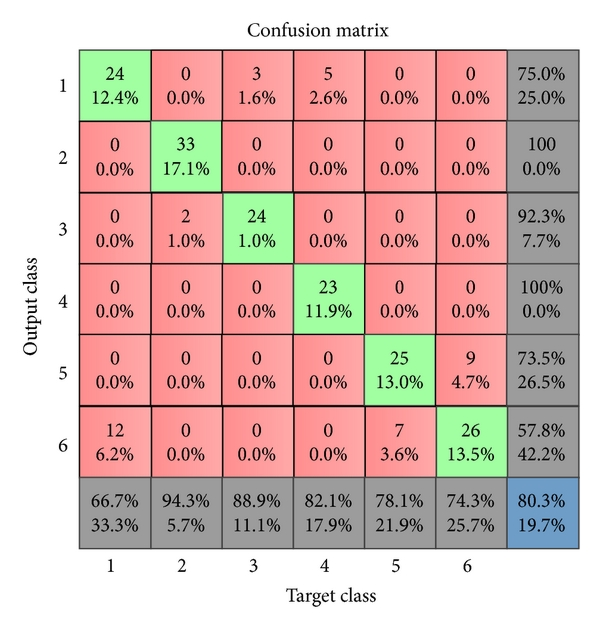
此外还有ROC curve的概念,也就是把FPR和TPR的变化曲线画出来。因为在分类任务中,我们有时候需要一个阈值来分类, 比如肿瘤大于1.5cm我们就认为是恶性。但是假设我们上下浮动这个1.5cm阈值,就会造成FPR和TPR的改变,所以我们引入ROC curve来观察变化。
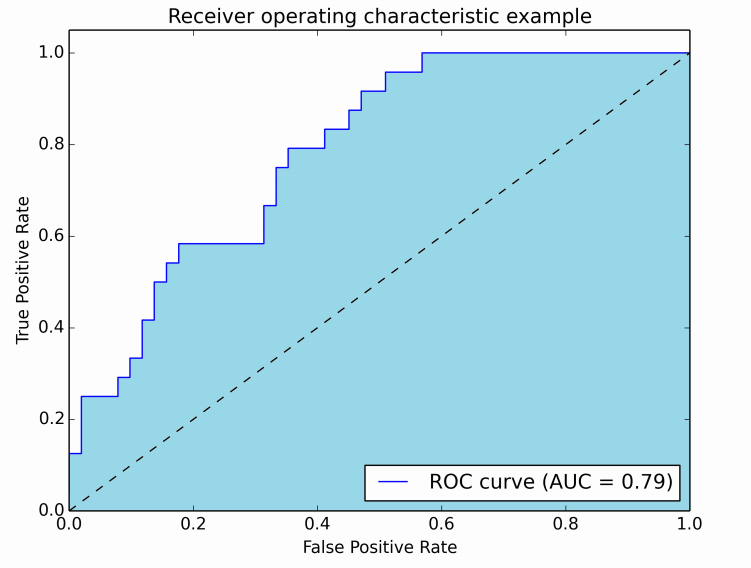
图中的蓝色折线就是ROC curve,底下的浅蓝色面积就是模型的accuracy,也叫做AUC值。这个曲线是要高于对角线的,因为对角线代表着AUC = 0.5,也就等同于扔硬币瞎蒙毫无意义。当曲线变成了y轴的时候也就是AUC = 1.0。所以当AUC的值变化0.01其实在正确率上就已经是提高了一个百分点,还是很有意义的。