宏观理解
我们已经了解了Faster R-CNN的过程和目的,其主要成就在于加速了人脸检测的速度并且提升了bbox的准确率。2016年诞生的MTCNN做的事情也是类似。下面一张流程图展示了MTCNN的训练过程,最后会得到带有人脸的bounding box以用于人脸检测和人脸上的5个landmarks以用于人脸识别。

从上图我们可以看出整个算法有3个stage,这三个stage是以级联的方式运作的。stage 1,浅层的CNN快速产生候选框;stage 2,通过更复杂的CNN精炼候选框,丢弃大量的重叠框;stage 3,使用更加强大的CNN,实现候选框去留,同时显示五个面部关键点定位。
在MTCNN之前的一个很广泛应用的级联是Viola和Jones提出的级联人脸检测器,利用Harr特征结合AdaBoost去实现高性能的实时训练。但是这种方法有一个很大的缺陷就是因为图片中人脸的姿势、光照或遮挡等原因致使能力直线下降,但是来解决这些问题的一个很好的工具就是深度学习,所以接下来我们来看看MTCNN的原理。
微观分析
我们已经看到了整个网络是由三个stage级联而生的,这是整个MTCNN的三个级联网络的过程图:
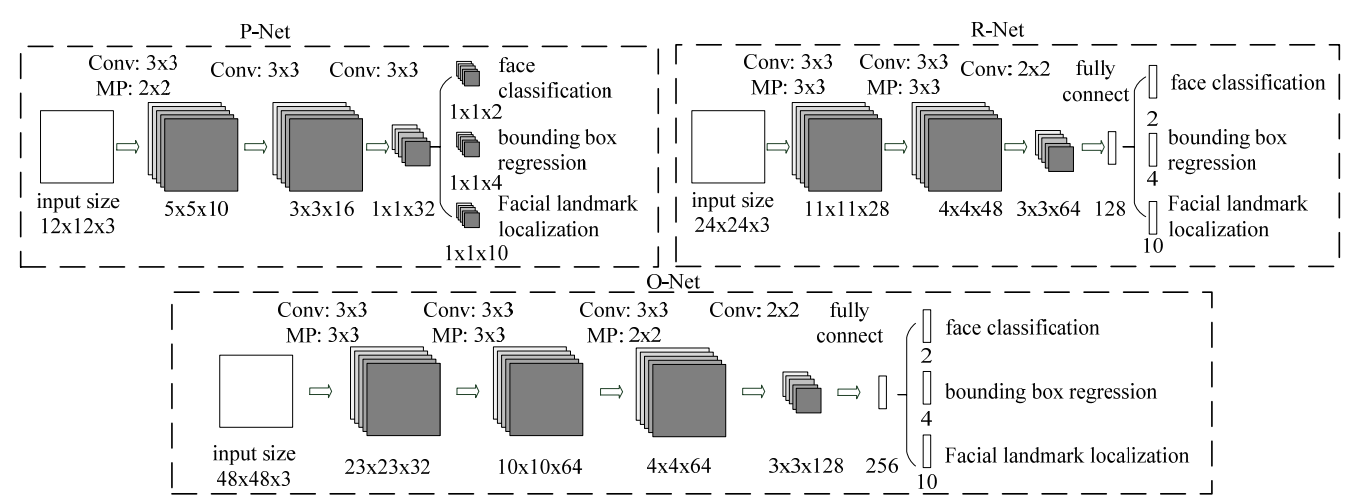
我们把这三个级联的网络叫做P-Net, R-Net和O-Net,所代表的含义就是Proposal Net, Re-fine Net和Output Net。
我们首先把原图拿来做图像金字塔resize成不同尺度的图片,然后用一个1212的sliding window在所有的不同尺度的图片中滑动来截取初始候选框,接下来把这些1212的候选框送到级联网络的第一个网络P-Net。
P-Net
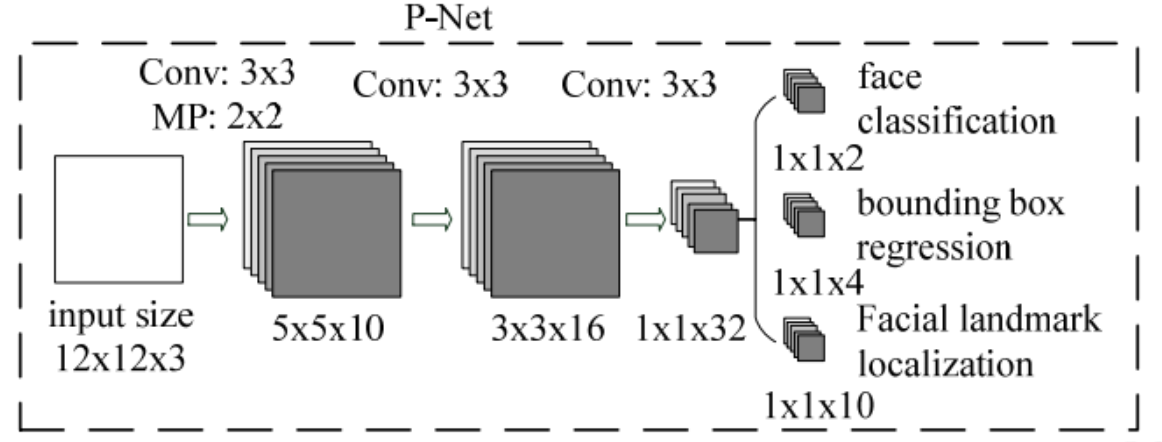
首先传进去的是一张1212的图片,可以看出来很小,也就是144个像素。接着做了10个333的卷积操作,stride可以看出来是1 ,最后得到一个101010的中间量feature map。然后做一个22的max pooling操作,stride为2,所以最后得出来5510的feature map。
随后也接着经过另外两个33的卷积操作把图像整合成11*32的特征向量。
最后在输出层中,我们可以得到3个结果。第一个是分类结果,通过2个1132的卷积得到两个数字,然后把这两个数字送给softmax来做分类得到是人脸的概率和不是人脸的概率。第二个是人脸的位置回归,用4个1132的卷积得到的4个位置信息。第三个是特征点信息,用10个1132的卷积得到5个特征点位置(x,y)所以是10个值。这5个特征点分别是两个眼睛,鼻子和两个嘴角。
我们可以发现之前学过的网络中的全连接层在P-Net中没有用到,其实这种结构叫做全卷积网络,也就是全部都是用的卷积层来实现的。它是有好处的。想想我们之前讲神经网络的时候说过,因为后面有了全连接,所以参数量固定了,所以输入的图片的size也是要固定的。这也是为什么我们之前都需要在神经网络的输入前resize一下原图。但是全卷积网络就可以接受不同大小的图片,没有了后面参数量的局限。
R-Net
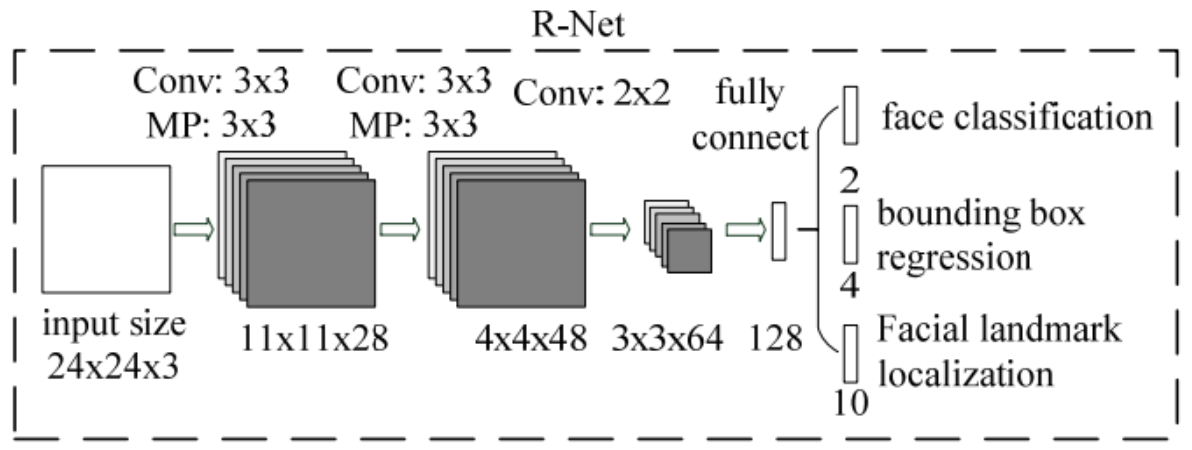
R-Net就不再是全卷积网络了。它的输入是从P-Net中输出的bbox在原图中裁剪出来的24*24的RGB image。然后经过3个卷积和一个全连接变成一个128维的特征向量。然后照样我们有3个输出,都是用全连接生成2,4,10个对应的值。
O-Net
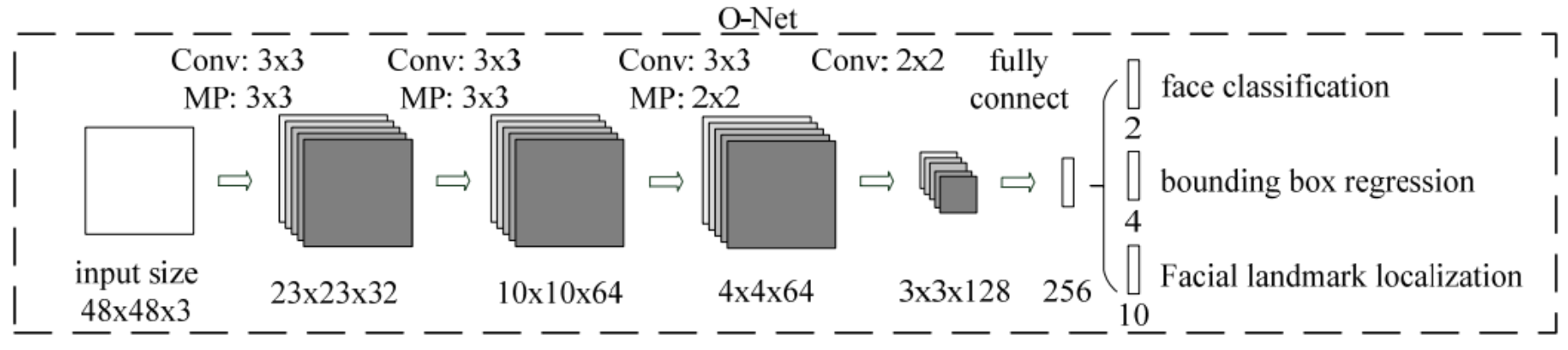
O-Net同理,它的输入是从R-Net中输出的bbox在原图中裁剪出来的48*48的RGB image。然后经过4个卷积和一个全连接变成一个256维的特征向量。然后照样我们有3个输出,都是用全连接生成2,4,10个对应的值。
我们发现在stage的传递中,前面的landmark并没有被后面的网络应用,这是为什么?这是因为在multi-task学习中,我们希望landmark即使在前面没有应用到,也要作为一个约束力告诉前面的网络我们还有一个landmark用来考量,这样在计算损失的时候不至于让bbox回归和分类把landmark带的很偏。
现在我们了解完所有的结构之后,就要看一下优化的损失函数了。
- loss functions 我们看到每个net都有3个输出,所以我们对应的也需要3个loss来计算。
- 对于face classification任务
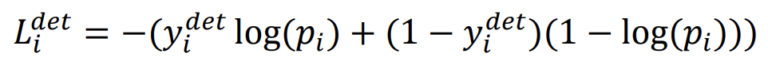
我们用的就是交叉熵函数。p指的就是对应的yi的概率了。
- 对于bounding box regression任务
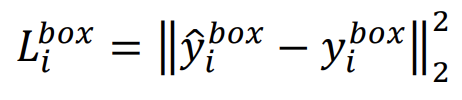
我们用的是欧式距离损失函数。我们知道一个区域的位置是用的左上角和右下角的坐标固定的,所以这个loss计算的就是groud truth的两个坐标和预测的框的两个坐标的位移大小。
- 对于facial landmark localization任务
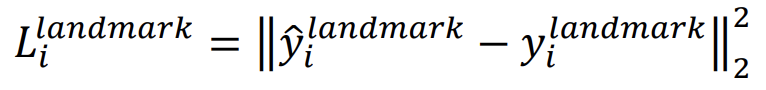
我们也用的是欧式距离损失函数。计算的也是这5个点到真实值之间的位移。
所以在最后整个网络的损失函数就是把这3个loss相加:
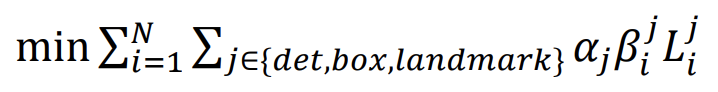
其中α是权重,因为在不同stage中的侧重点不一样,所以如果我们更希望P-Net更侧重候选框的选择而不注重landmark的生成,则可以把landmark的α设置的小于R-Net和O-Net。作者使用的权重分配是这样的:在P-Net和R-Net中,α_det = 1, α_box = 0.5, α_landmark = 0.5。在O-Net中,α_det = 1, α_box = 0.5, α_landmark = 1
用MTCNN做出来的效果就像这样啦
