宏观理解
学习R-CNN算法之前我们要知道他是干什么的。计算机视觉领域里有一个很重要很基础的分支是物体检测,它做的就是把一张图片的前景和背景区分开,然后给所有的前景进行分类。比如下图中的前景包括car,dog,horse和person。物体检测也就是得到一张如图一样的结果。这也是监督学习的一种,但是在数据集中他们经常是包含这张图片、人工标注的前景bounding box和对应的分类。在传统的机器学习算法中要做到这样的结果分为两步,也就是对应着我们之前说过的HOG + SVM类似,首先是要找到一个函数(HOG)可以输入一张图片输出一些特征,然后再有一个函数(SVM)输入这些特征再输出分类类别label。那么R-CNN则是基于深度学习来完成这个任务的方法。它的全名是Region CNN,我们知道CNN可以帮助我们分类图片,那么Region也就可以帮助我们找到图片中的特征。当然除了R-CNN还有很多比如YOLO, SSD,还有人尽皆知的Fast R-CNN, Faster R-CNN等等。这些以后都会依次介绍。

微观分析
下图是论文中给出的步骤,第二步中的region proposals代表我们要在图片中找到的前景,然后把这些候选框(大概1~2千个)抠出来,交给CNN来特征提取,最后交给分类器SVM分类。
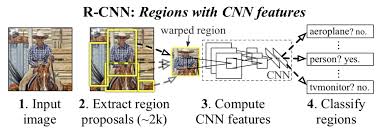
总结一下,我们可以把整个R-CNN算法分成4个步骤:
- 生成候选框(使用selective search)
- 对每个候选框用CNN进行特征提取
- 把提取出来的特征送到分类器(默认SVM)中进行分类
- 使用回归器对候选框的位置进行修正
我们对以上4个步骤进行逐一讨论。
- 生成候选框(使用selective search) selective search方法做的事情是把一张图分割成很多很多很细节的小区域,举个例子,假如图片中有五星红旗🇨🇳,那么使用selective search后,不仅仅整个五星红旗会被框出来,连里面的5颗星星也会被框出来。这种手段叫做过分割。我们不妨把分出来的所有小区域存进一个集合R中。下一步则是在集合R中循环所有的区域,把他们两个的相似度存进另外一个集合S中。然后我们在集合S中排序,找到相似度最高的两个区域,我们把这两个区域合并(集合S中也就对应删除掉相应信息),然后放到集合R,形成新的候选框。随后因为有了新的候选框,我们要计算新的候选框和其余子集的相似度,然后重复以上过程每次两两合并最终直到整张图像合并成一个区域为止,这时集合S也就空了。伪代码如下:

那么我们怎么直到两个小区域的相似度呢?我们可以按照以下的顺序进行合并,如果颜色全部类似,那么就往下一步来按纹理合并,以此类推:
- 通过颜色直方图中颜色相近的
- 通过梯度直方图中梯度相近的(梯度可以理解为图片的条纹走势类似)
- 合并之后总面积小
- 合并之后总面积在bounding boxes中所占比例大
整个这个过程完成之后,我们把所有在集合R中的候选框全部拿来用,这就完成了第一步通过selective search选取候选框。
- 对每个候选框用CNN进行特征提取
我们拿到了集合R中的候选框后,发现什么玩意都有,而且乱的一逼。这种东西怎么能直接送给CNN呢,我们在CNN中提到过,它的输入都是一定的不能变化。所以在送之前,我们需要对所有的候选框进行resize,那么怎么resize也是有讲究的,论文中提到了两种方式:

- 各向异性缩放:如图(D)所示,也就是平民玩家的愣resize,啥都不用管,大小弄成一样就好。但是这种方法对CNN的特征提取肯定不好。
- 各向同性缩放: (1) 先扩充再裁剪:如图(B)所示,vip玩家,先把原图扩展成正方形,然后再裁剪。 (2) 先裁剪再扩充:如图(C)所示,vip玩家,先把原图裁剪,然后padding扩展。
剧情反转,穷人的技术流也能取胜,作者最终通过实验,表明各向异性缩放、padding=16的精度最高。但是不证明在其他的地方各向异性缩放也会是最好的,所以多多实验总是好的。
最后就很平常的送给一个CNN就好,至于那么多种CNN结构可以选,就是我们的自由了。作者选的是AlexNet(不了解AlexNet可以看这里),那么最后通过卷积后得到的就是4096维的特征向量,但是与AlexNet不同的是,作者并没有使用最后一层1000维的分类器,而是把全连接的4096维提取出来,作为当前图片的特征,再给SVM进行分类。
- 把提取出来的特征送到分类器(默认SVM)中进行分类
我们对每一种类别都训练一个SVM分类器,输入就是上一步传来的4096维特征向量,输出就是该分类的置信度。
- 使用回归器对候选框的位置进行修正
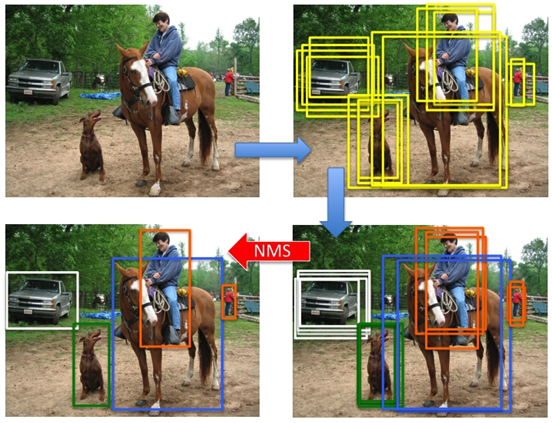
同样的那4096维的向量,我们送给SVM的同时也会送给一个线性脊回归器用来对位置进行精修。那么输入的就还是4096维特征向量,输出的就是两个坐标点(左上和右下两个坐标点来固定一张图的位置)的平移因子和缩放因子的4个数字。 好。到目前为止我们已经可以在一张图中找到物体位置并有一个分类。但是还有一个问题没有解决,就是在使用SVM分类之后,同样一个物体,可能会有多于一张图片的置信度都很高,因为我们在selective search中找的候选框实在是太多了,难免有及其类似的两张图。比如下图中的样子。那么怎么把同一张脸上的相差无几的几张候选框最终只保留一个最好的呢?

IoU (交并比,Intersection-over-Union)

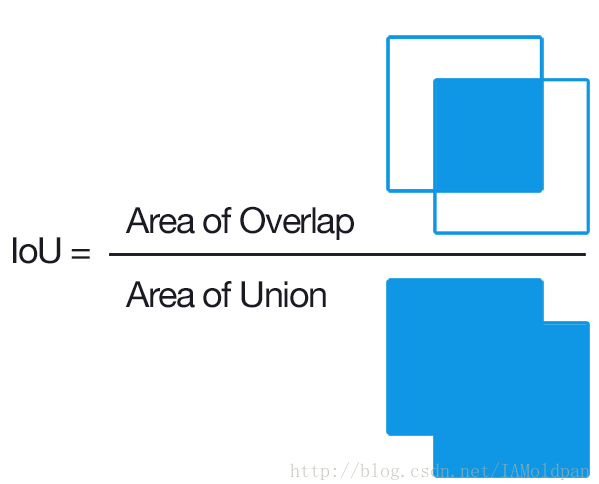
如图中A是我们人工标记的ground truth label,B是我们的识别结果,很明显它并不好。IoU计算的就是两张图片的交和两张图片的并的比例是多少,如果这个数字很大,意味着这两张图片很是相近也就证明我们预测的很好。如果很小那么就说明我们的预测很失败。这个界定的阈值我们一般设置为0.5-0.8之间,根据自己模型的好坏来调整。
NMS(非极大值抑制,Non-Maximum Suppression) 在我们知道IoU怎么做之后,我们就通过NMS来删除一些候选框。首先我们选取置信度最大的框A,然后计算其余的候选框对A的IoU,把IoU大于阈值(0.3~0.5)的框全部删除。然后剩下的候选框中除了框A再找出最大的候选框B,然后重复以上过程。
终于做完了。放个图回顾一下整个流程:拿到一张图片 -> 用selective search选取候选框 -> 用CNN提取候选框特征 -> 用分类器对特征进行分类,同时用回归器对位置进行精修 -> 分类后使用NMS对候选框进行挑选。