Case Study
我们这里主要介绍几种常见常听说的模型,既是对之前讲的概念进行更深的理解,也是在以后我们可以有思路怎么搭建自己的模型更好。这里主要是讲
- LeNet-5
- AlexNet
- ZFNet
- VGGNet
- googLeNet
- ResNet
我们在分别讲5个模型之前先看一下他们的丰功伟绩,这些模型都出自ILSVRC竞赛。为了更好的膜拜这些模型,我一定要说人类识别这些图片的错误率在5%左右,可见最后的ResNet已经达到了超过人类的识别能力。

LeNet-5
这是Yann LeCun在1998年ILSVRC构建的卷积网络,名列第一,也是convnet投入重点研究的开端。它的架构如下图所示:
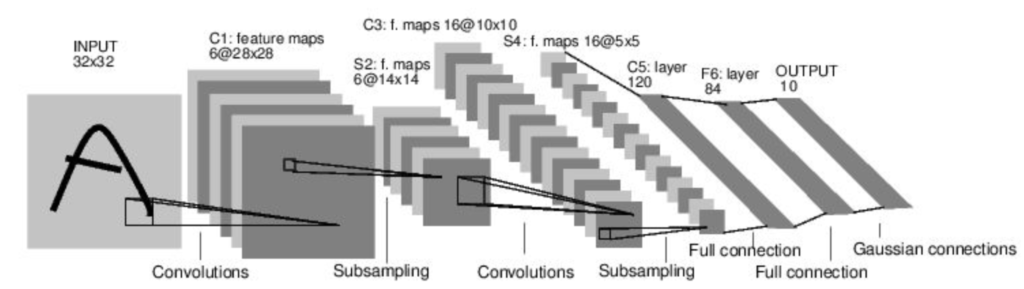
输入一张3232的图片,经过C1卷积层得到28286的feature map。feature map就是在输入经过卷积后的结果。我们可以推算出来他的kernel用的是556并且步长为1。然后一个S2下采样的池化层把纬度降到14146,也可以推算出来pooling用的22并且步长为2。接着就又是一层卷积C3和一层池化S4。最后连着两层的全连接层把纬度降到120和84,最后用高斯连接输出10个分类概率。
所以总结起来就是CONV-POOL-CONV-POOL-FC-FC-GAUSSIAN
AlexNet
Alex Krizhevsky, Ilya Sutskever and Geoff Hinton在2012年参加ILSVRC竞赛的冠军模型,其实很像LeNet但是比它更深更大一些,这也是随着硬件的发展的必然趋势。
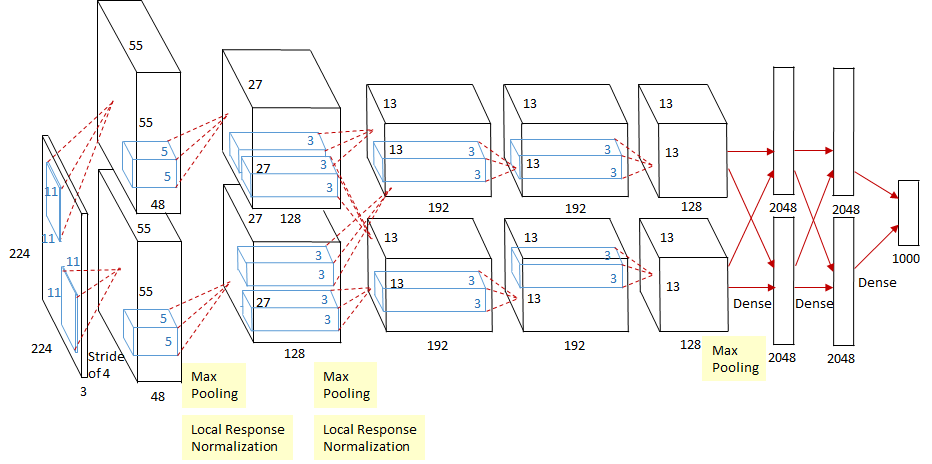
这是在论文中给出的结构图,因为当时的CPU内存不大所以分成了两个batch在两个CPU上进行训练,但是在如今其实没有这个必要了,我们完全可以合并成一个pipeline,正如下图:
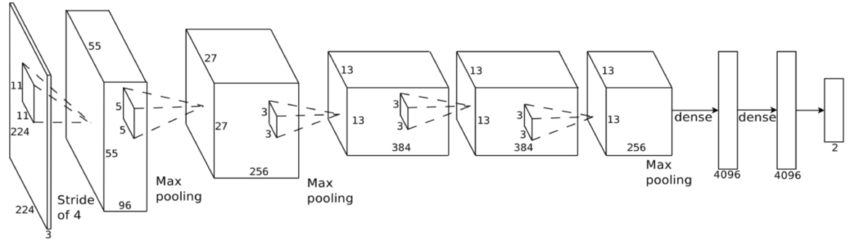
这两个图是一一对应的,所以结构相同。如今如果想复现AlexNet就参考下面就好。但是有一点需要提醒的是,虽然论文中给出的input image size是2242243,但是经过推算它不可能可以得到555596的feature map。所以在后人的实现中,都把224改成了227。据说Alex声称就是224但是没有给出原因所以我们就按照227吧。
也很容易看出来他的结构,先是通过一个111196的kernel并且步长为4,得到555596的feature map。那么这一层有多少个参数?就是1111396个呗。然后第二层是池化层,用的33的filter并且步长为2。接着跟着一个正则化层,把反向传播导致的偏移矫正回来。然后紧接着就是重复卷积和池化的操作了。总结下来他的结构如下还有超参数的选择:
- [227x227x3] INPUT
- [55x55x96] CONV1: 96 11×11 filters at stride 4, pad 0
- [27x27x96] MAX POOL1: 3×3 filters at stride 2
- [27x27x96] NORM1: Normalization layer
- [27x27x256] CONV2: 256 5×5 filters at stride 1, pad 2
- [13x13x256] MAX POOL2: 3×3 filters at stride 2
- [13x13x256] NORM2: Normalization layer
- [13x13x384] CONV3: 384 3×3 filters at stride 1, pad 1
- [13x13x384] CONV4: 384 3×3 filters at stride 1, pad 1
- [13x13x256] CONV5: 256 3×3 filters at stride 1, pad 1
- [6x6x256] MAX POOL3: 3×3 filters at stride 2
- [4096] FC6: 4096 neurons
- [4096] FC7: 4096 neurons
- [1000] FC8: 1000 neurons (class scores)
- 用ReLu作为激活函数
- heavy data augmentation(数据增强,比如剪切旋转增加噪声进行干扰)
- dropout = 0.5(只在最后全连接用)
- batch size = 128
- SGD Momentum = 0.9
- Learning rate = 1e-2 当在验证准确率很艰难优化的时候reduced by 10
- L2 权值衰减 = 5e-4
ZFNet
ZFNet是2013年的冠军模型,由Matthew Zeiler and Rob Fergus构建。他们是在AlexNet的基础上进行的改动,比如调换了超参数,增加了中间卷积层的大小等等。具体来看一下:
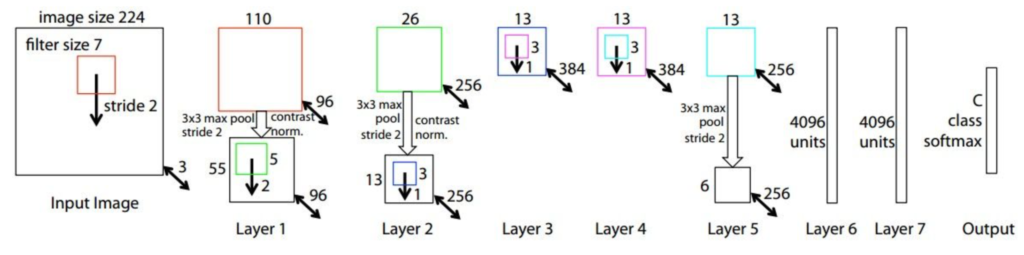
可以对比看一下,其实结构基本没变,只是进行了微调,比如在第一个卷积层把kernel从1111并且步长为4换成了77步长为2,因为他们觉得步长太大会跳过很多信息。在第3,4,5卷积层中把filter的个数从384,384,256换成了512,1024,512。其他结构没变,再根据新的结构进行超参数选择。
VGGNet
这个模型是2014年ILSVRC的亚军模型,由Karen Simonyan和Andrew Zisserman构建。我们可以看出来它的层数更多了。论文中给出的A – E是几种架构,最后经过实验D是表现最好的,所以我们就讨论D。
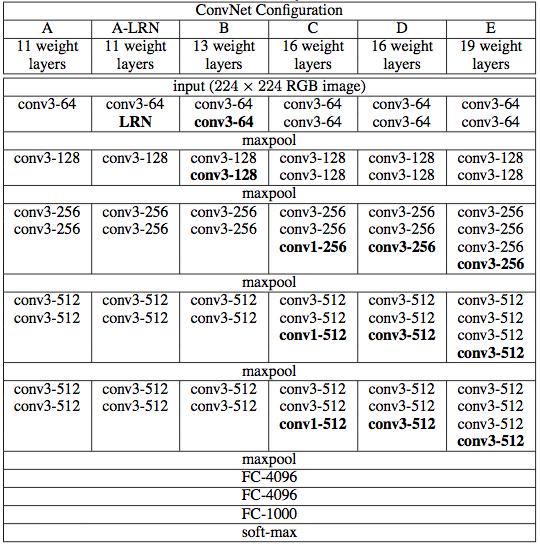

我们可以直接看后面的参数分析图,整个架构layer很多,并且参数也很多,这也就需要内存的保证,不是一般机器就能handle的了的。93MB一张图片,如果你需要train一万张就是930G的内存几乎要有1T的机器,当然这仅仅是一万张,工程中的图片数量都是百万千万级别。我们可以发现需求最大的就是全连接层,一个图片就要上亿个参数,这无疑是不好的。但是有个窍门可以节省很多,比如原图中是775124096,我们其实可以在77*512当中进行一个求平均最后我们只要512个平均数,再通过全连接就会减少49倍的参数和内存。并且不会很影响效果。这也正是下面要说的googlenet使用的方法。
GoogLeNet
这也是2014年诞生的模型,是ILSVRC的冠军模型。由来自谷歌的Szegedy et al创造。他最创新的点在于引入了inception模块,用来减少模型的参数量。
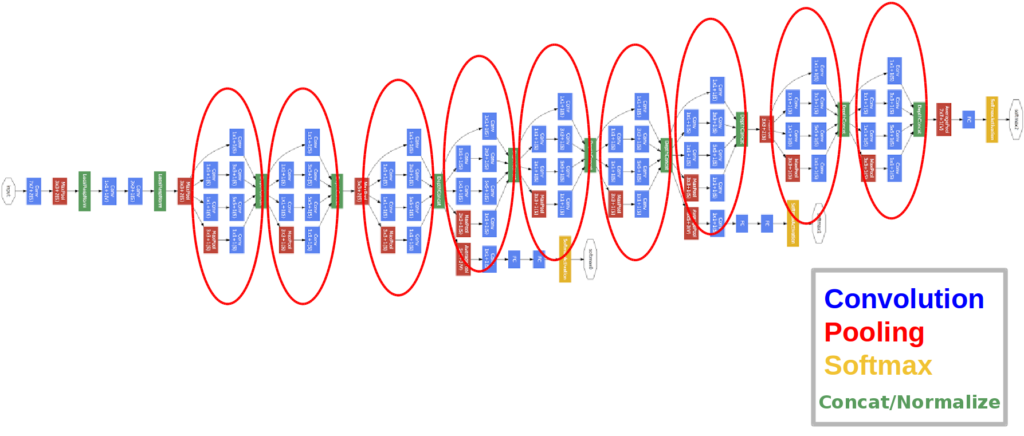
每个用红色圈起来的都是一个inception module,所以看起来虽然很酷炫复杂其实就是一堆相同的东西串联而成,我们放大看一下inception module是什么样的:
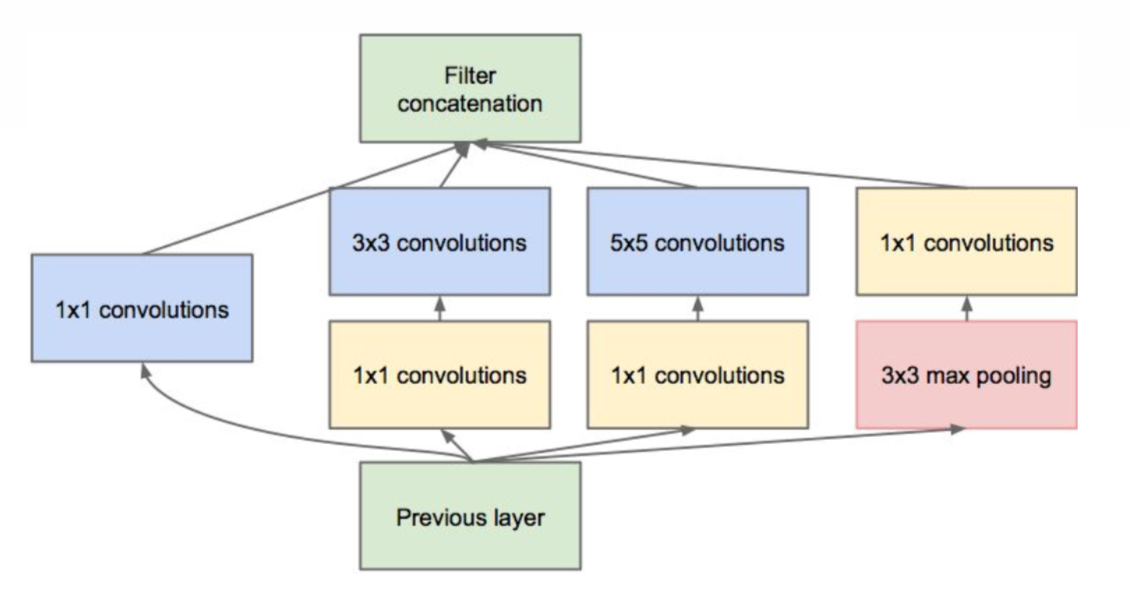
为什么要构造inception module呢?因为从上面介绍的模型看下来,是不是发展的趋势是模型越来越深,layer越来越多?是的,事实证明层级越多模型表现力越好,但是遇到的瓶颈是,如果我们把层数增多了,训练会慢,而且参数量会增大,内存又不够,我们总不会希望创造一个根本世界上没有机器可以运行的模型出来。所以google构造inception的目的就是在保证深度(layer数量)和宽度(神经元数量)的同时,减少参数的产生,以达到一个巨大的网络也可以在我们每个人的普通机器上运行。图中输入进来之后会做4个操作,然后在最后输出结果的时候把4个结果拼接在一起。起初google引入inception的时候是只有11,33,55的卷积和一个33pooling的,但是后来发现出来的结果厚度过大,所以升级版的inception就多来三个1*1的卷积,用来降低厚度,把参数缩小了4倍。
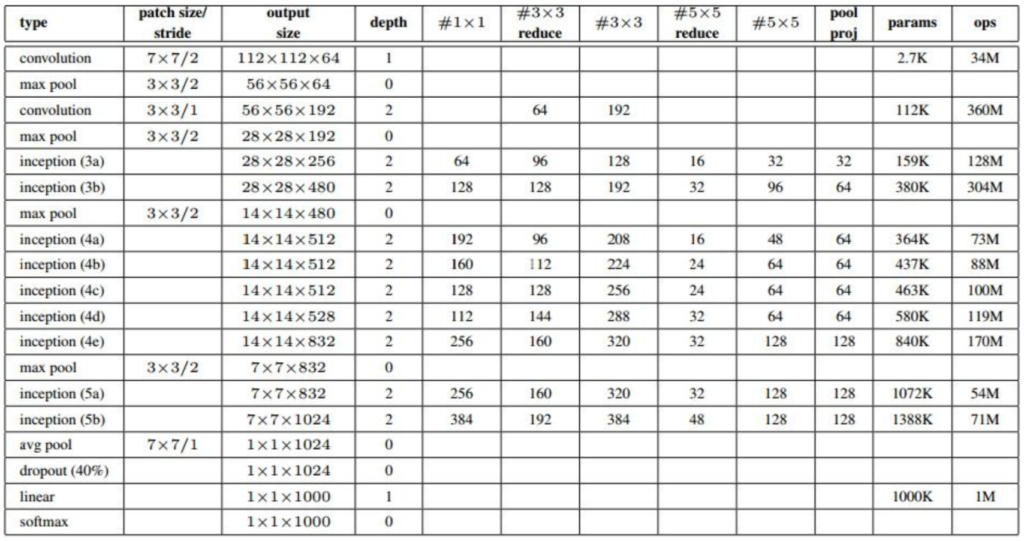
上图是googLeNet整个的22层layer架构,#33 reduce列代表的是在卷积层之前经过了多少个11的kernel。
最终整个网络的参数总和达到了500万个。相对于VGGNet的1.4亿个, AlexNet的6千万个,已经节省很多了。并且还可以达到超过他们的正确率。
ResNet
这是ILSVRC 2015年的冠军模型,由微软亚太研究院的Kaiming He et al构建。它由152个layer组成,回想一下我们第一个LeNet -5才5层,AlexNet才8层,VGGNet才19层。但是在论文中他们也写到了不是一味的增加layer就可以提高正确率的,为此他们还模拟了一下单纯的一直增加layer和他们使用的ResNet有什么区别:
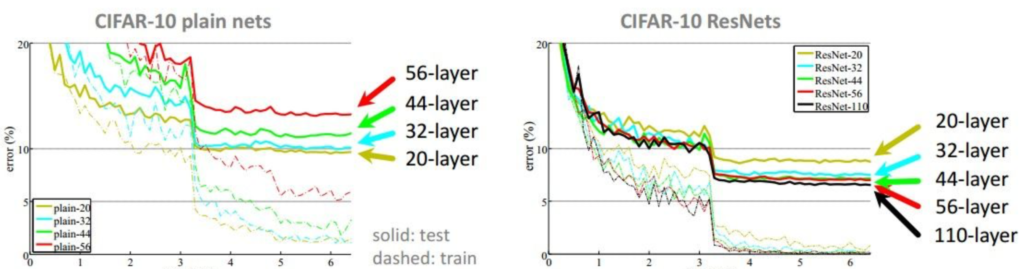
plain nets就是我说的一味的单纯增加深度,反而会发现越深的时候test错误率反而越来越高了。可是他们使用ResNet的时候却可以保证随着层数增加错误率也在不停的降低。为什么呢?
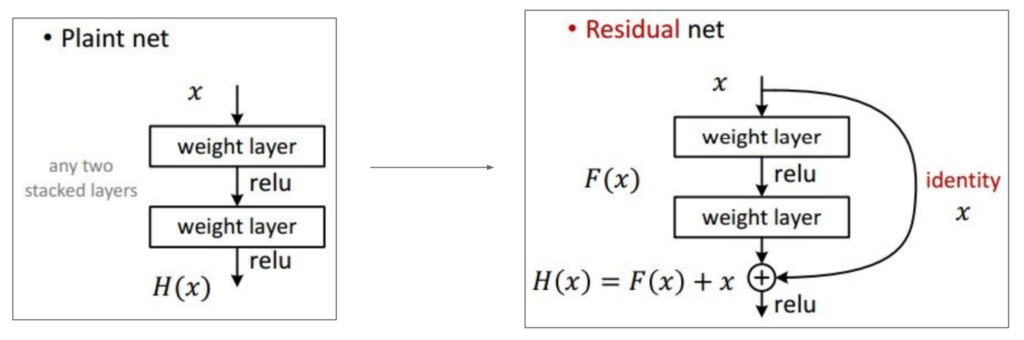
上图中左边是我们非常单纯的增加layer的方式,但是右边他们不仅把上一层的输出传给下一层,还把上上层的输出也给到了下一层输出的结果。这样的好处是在反向传播的过程中不仅要一步一步像回传,还要跳跃着传,在做加法的时候把梯度分散,这样最后一层的梯度也可以很快的回传给第一层,会减小在回传的时候梯度对原图的一个扭曲,可以在第二次正向传播的时候得到更相近的图片。这也是为什么单纯的增加layer会越来越改变原图的信息使得效果越来越差。
- Batch Normalization after every CONV layer
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
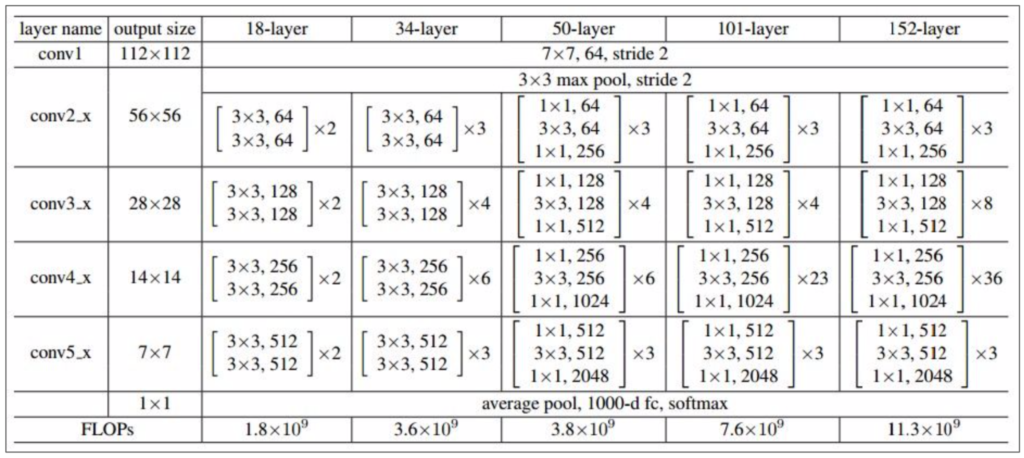
最后这是ResNet的整体架构和参数选择。我们在convnet中已经可以默认使用这种模型了。