宏观理解
卷积神经网络我们主要用在图片的处理上,它是在神经网络的思想基础上,把神经网络的weight组合成了一层过滤网,把原图一遍遍的过滤来提取出来最主要的特征。现在的图片分类几乎都是在用卷积网络来做,神经网络更多的还是在一些像年龄、价格、所属层级的一些分类和回归问题上。
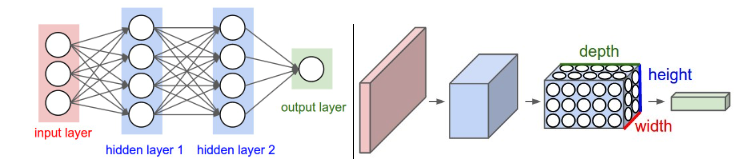
下图左边就是我们说过的神经网络的架构,右边是卷积神经网络的架构。能看出来还是有很大区别的,但是这种区别在掌握了神经网络之后就很好理解了。
微观分析
卷积网络主要是由几种不同操作的layer组成,他们是convolutional layer(卷积层),pooling layer(池化层)和fully connection layer(全连接层)组成。
下面对这几种layer分别介绍一下。
convolutional layer 卷积层
卷积层是卷积网络最核心的提取信息的layer,他的作用是在已有的输入后,把和输入具有信息等价的输出传给下一层。可以理解为卷积层做了一个信息的重构。
对输入信息进行卷积操作的是一个叫filter或者kernel的矩阵。我们以后就统一叫kernel。kernel中的值就是这个卷积网络的参数,在反向传播中我们会不断优化这些值,一开始我们可以随机初始化这些值。
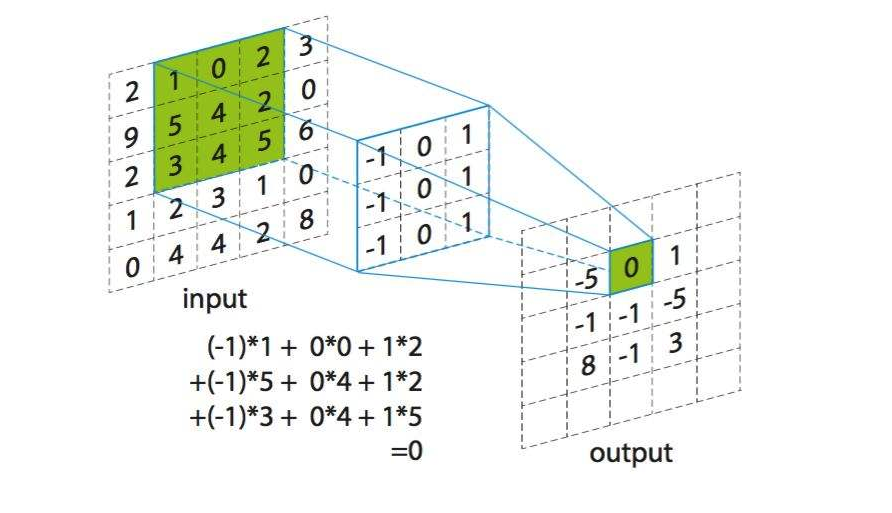
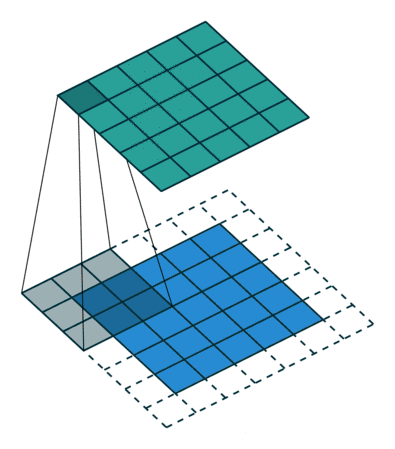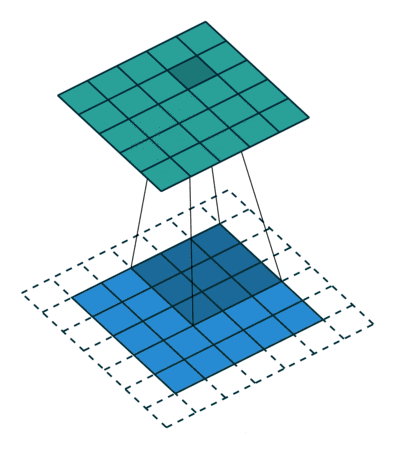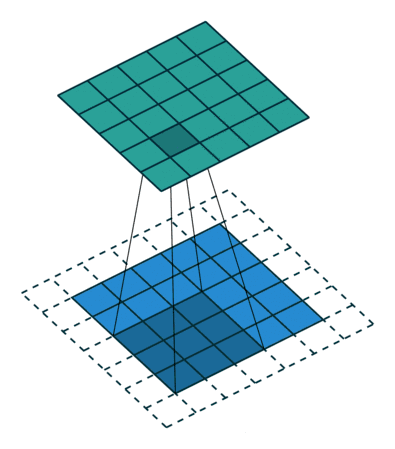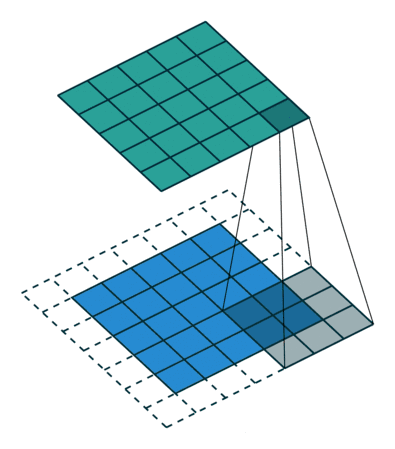
第一张图中左边为输入矩阵,比如说rgb色道中的一个,然后中间的就是卷积核kernel,右边为输出。kernel会一步一步的扫一遍输入,每次到达一个位置时计算这两个3*3矩阵的乘积加和,给到输出。所以每次计算后的输出都是一个值。下面是一个动图更好的理解一下kernel是怎么扫的输入矩阵。
在动图中四周的白色边框叫padding,因为我们可以看出来当kernel进行卷积操作的时候,输出会比输入的矩阵小。如果我有一个上百层的卷积网络,那么矩阵会缩小的很快。在第一张图中输入为55,经过33的kernel后输出就是3*3 。但是在卷积层我们并不想损失任何信息,我们还想得到相同大小的输出。这时候就像动图中的我们可以在原图上pad一圈0,这样长和宽都扩大了2,最后输出的矩阵大小就和我们输入矩阵大小相同了。关于padding其实有也有很多方法,可以pad 0,也可以pad相邻的数字。但是为了让padding更小的对输出产生影响,一般默认都是pad 0 。
那么我们在pad的时候怎么知道要pad几圈呢?有一个公式可以计算出来:padding = (kernel_size – 1)/ 2 。比如第一张图中,kernel_size等于3,那么我们就需要(3 – 1)/ 2 = 1圈的padding。
除了padding算是一个超参数以外,还有步长(stride)。顾名思义,就是kernel在扫描input的时候是每次往右或者下走一步还是更多。比如在下图中,步长stride就不再是1了而是等于2,所以横竖都只能扫描3次,得到3*3的output。
以上介绍的都是二维矩阵,但是我们知道在处理图片的时候都是rgb三个色道来表示一张图。所以我们接下来让input和kernel变得更复杂一点。
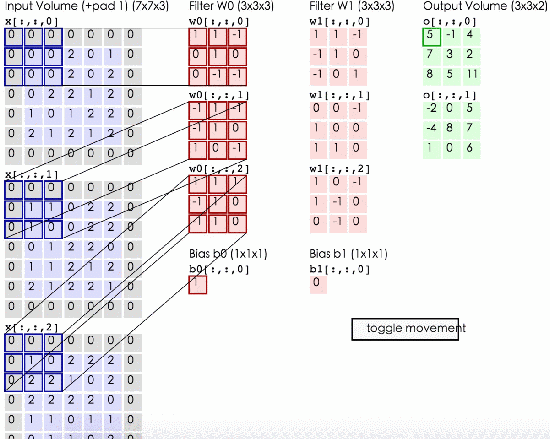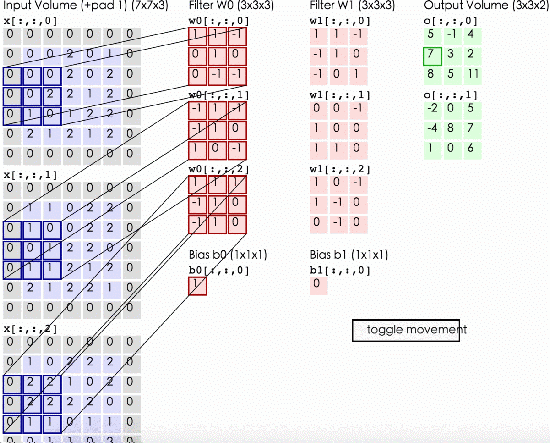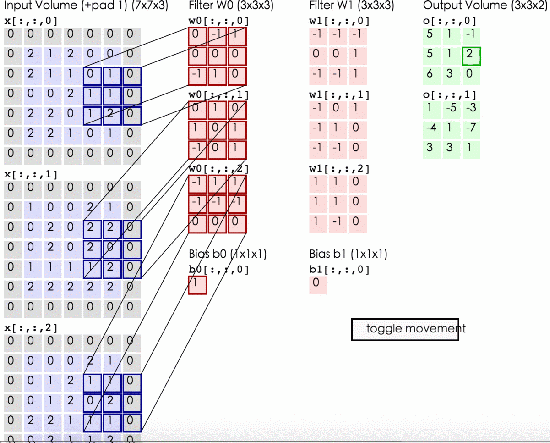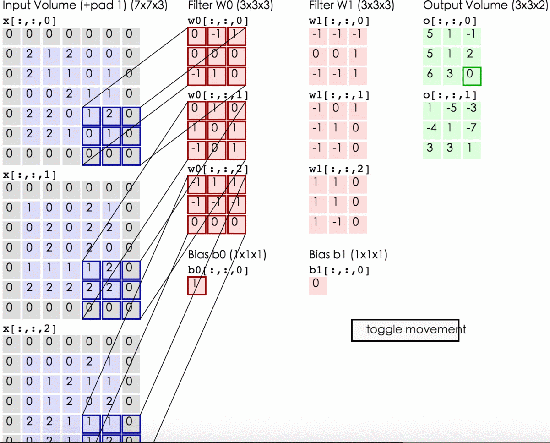
上图就是标准的3色道输入size = 773,然后两个kernel size = 2333,输出是一个33*2三维矩阵,步长stride = 2 。输入矩阵先用第一个kernel相乘,得到一层output,再和第二个kernel相乘得到第二层output。因为我们可以看出来input的第一层和kernel的第一层相乘,input的第二层和kernel的第二层相乘,input的第三层和kernel的第三层相乘,所以我们在初始化kernel的时候要遵守的就是input和kernel深度相同。
我们有公式可以计算出来output的大小:size = (input_size – kernel_size)/ stride + 1 。例如上图中size = (7 – 3)/ 2 + 1 = 3 。output的深度一定是和kernel的深度相同。所以是332
那么我们这层网络中有多少参数呢?从图中可以看出来是2个kernel每个27个值再加一个bias。就是2 * (333 + 1) = 56个参数。
我们在卷积操作完了之后,一般会跟一个下采样的layer,就是池化层pooling layer。
pooling layer 池化层
池化层的意义就是下采样。来提取不同的图片轮廓。理解完卷积层再看pooling就很简单了。一般分两种:max pooling和average pooling。
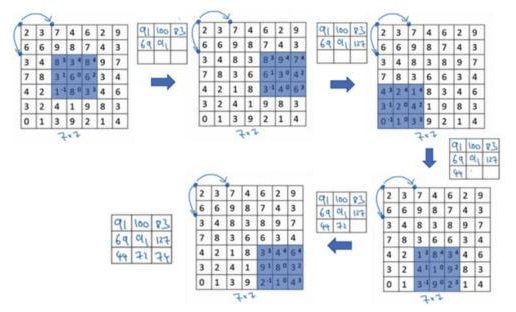
先看max pooling,这回我们没有kernel了也就没有网络参数了,仅仅是在输入矩阵中像卷积操作一样扫描一遍,max pooling就是找出当前扫描框中最大的那个数字。但是类似卷积操作的,我们也要设置池化的大小和步长,比如下图就是一个大小为2步长为2的pooling操作:
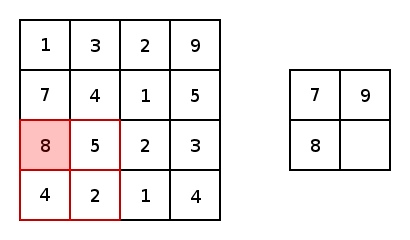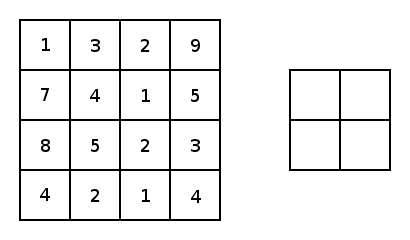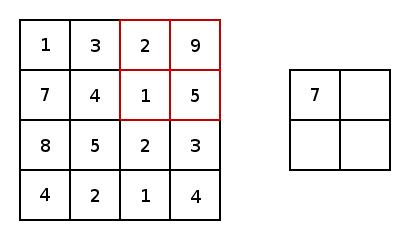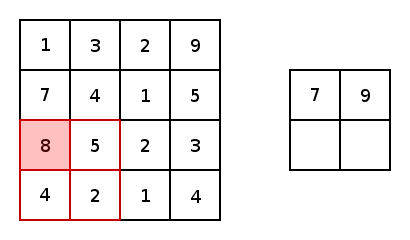
所以很简单,如果我们用max pooling,那么最后颜色深的边框信息将会被我们提取出来。average pooling道理一样,就是求出当前扫描框中所有值的平均值即可。
fully connection layer 全连接层
全连接层是在一堆卷积池化卷积池化完成之后,最后接一个甚至更多的全连接层。那么意义在哪?我们之前说过卷积是为了重构信息,池化是为了提取重点信息比如边缘,那么到目前为止我们得到的信息都是零碎的,好比你拿照相机左边照一下,右边照一下,上面照一下,下面照一下,最后通过全连接层把这些零碎的信息进行整合来给出一个判断。所以专业术语的说,卷积和池化的意义在于信息提取,全连接的意义在于决策分类。既然要重整零碎的信息,那肯定一点也不能放过,也就是为什么叫“全”连接,就是把上一层中输出的信息,全部的当成全连接层的输入,所以在这一层中的参数相当的大。上个图体会一下:
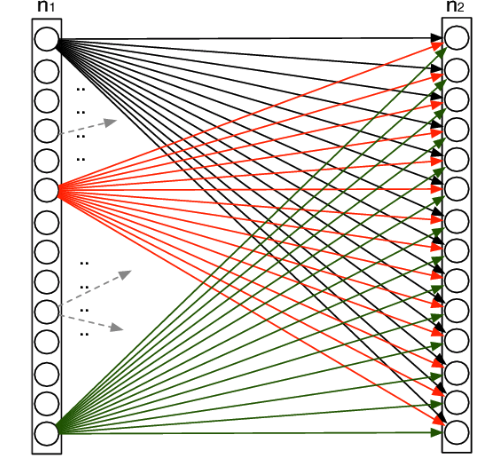
n1就是上一层的输出,他的输出要全部每一个都要和全连接层相连来进行信息合并再决策,本质上就是一个逻辑回归的操作,可以感受到参数量的巨大。
举个例子全连接层的工作是什么:
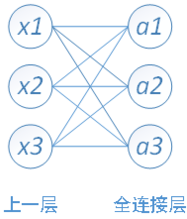
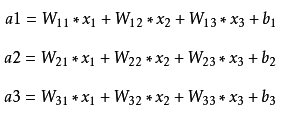
x是全连接的输入,a是全连接层的输出。可见这个weight矩阵的个数就是input * output 加上bias的个数output,所以一共是(input * output)+ output个参数。
我们一般在这一层中用的是relu而不是sigmoid。其实我们可以忘掉sigmoid这个东西,几乎现在很少有人在用了。
总结
最后总结一下,卷积网络包含的就是以上3种layer,通过不同的组合和连接方法来创造不同的卷积网络,那么为什么卷积网络就可以做到我们希望的结果,这也就是要从几个layer的作用分析了。首先我们知道卷积的过程是一个可以提取周边信息的操作,这也是为什么没有人用22的kernel来卷积,因为33的时候总能提取到中间那个点的周边信息,所以卷积操作给网络提供了局部相关性。其次卷积和池化的操作并不会改变图片原本的像素位置,而是在原地提取和采样,这样即使拿一张猫在左边的图来学习,也可以判断出一张动物在右侧的图中是否是猫,所以提供了空间不变性。再有,因为我们每次卷积只有一个kernel,所以我们叫参数共享,正是因为这种特质,我们既可以降低模型参数数量,又能控制模型复杂度防止严重过拟合。最后就是比较偏向神经科学的解释,卷积网络是模拟的人类视觉系统,从晶体看到物体以后,要通过整个大脑进行传输,这个传输过程就是提取边缘信息最后进行整合。想一想我们判断一个物体的时候是不是先勾勒的是物体轮廓再进行判断?所以卷积池化+全连接就是模拟了整个这个传输过程。
下一篇我们会讲一些比较知名的网络结构,了解它们的原理和思想,不仅有助于我们更好的构造自己的卷积网络,也可以在迁移学习中选择适合自己任务的模型。