接着之前的神经网络第一篇。
这篇文章我们来了解一下更多更专业的细节,来帮助我们更好的训练出神经网络。
- Data preprocessing
对于神经网络来说,一般的分类回归问题和普通机器学习模型的数据预处理基本相同。但是对于图像特征的处理,就是重点了。
我们知道一个图像分RGB三个色道,每一个像素值都是0-255。那么我们对图像数据的预处理可以做mean subtraction,比如像AlexNet对每个像素值减去整张图的像素值mean;也可以像VGGNet一样减去每个色道的mean。
归一化也是预处理很重要的一步,目的是把所有的特征点都归一到同一个scale里。一般我们有两种方法,第一种是把整个数据集除以它自己的标准差,第二种就是min-max归一化。流程见下图:
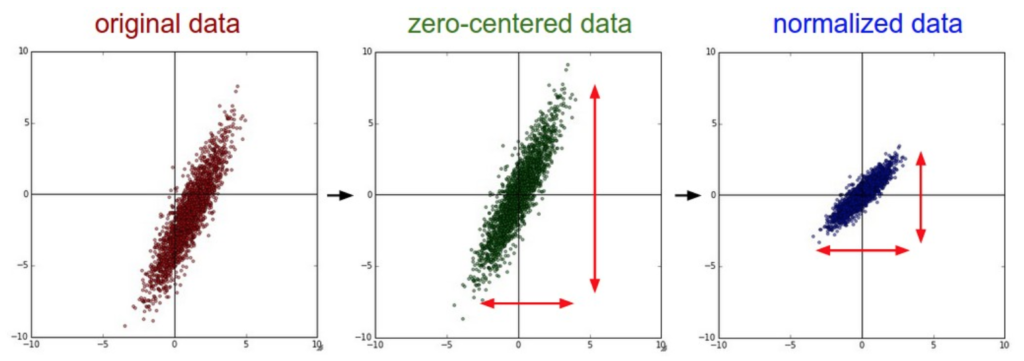
左图是我们拿到的raw data,经过减去整个数据集的mean值,我们可以得到原点对称的数据,就是中间的图。最后再经过归一化得到右图。当然如果像图片的输入,就已经是0-255,就不再需要归一化处理了。
PCA和whitening白化也是我们预处理的方法,因为我们拿到的数据大部分都是特征之间相关性很高,所以自带很多冗余信息,这样会加大训练的难度。经过PCA降维之后,我们可以找到一个新的特征矩阵,这个新矩阵满足1. 特征之间独立。2. 新矩阵和原矩阵的方差一样。也就是说,我们在不损失信息的前提下,降低了数据维度,让数据特征之间增强了独立性。PCA不细说了前面有文章讲过。所谓的白化就是在PCA得到的新矩阵上进行归一化处理。这个过程见下图:

在PCA处理后我们根据所选取的top 144个新特征向量组成新的数据集,也就是图3,然后在新的数据集中进行归一化。最终得到的白化结果如图4。
- weight / bias 初始化
权重的初始化也对神经网络的性能产生一定影响,如果倒霉初始化的不好,会发现怎么优化都得不到好的结果。
有的教科书中在讲解神经网络的时候用的都是把权重全部初始化成0,首先肯定是不能用0来初始化的,因为一旦所有的weight都设置成一个权重,在反向传播的过程中所有权重的更新值也都会一样,毫无意义。
我们一般会用的初始化有高斯分布随机初始化,还有Xavier初始化(w = np.random.randn(in, out) / np.sqrt(in)),in和out是前一层和下一层的node数量。还有如果你想用ReLU作为激活函数的时候,需要在Xavier初始化中改变一下分母(w = np.random.randn(in, out) / np.sqrt(in/2.0))。
对于bias我们可以初始化为0或者一个很小的数值比如0.01用于ReLU作为激活函数的时候。
- Batch Normalization
这是一个近几年才刚发的论文提到的方法。由于我们的反向传播过程中改变weight改变激活函数输出值,我们一开始标准化完的数据集可能会产生偏移,会导致训练越来越慢。Batch Normalization做的就是在神经网络中添加一些层,在这些层中,我们把传过来的神经元强行拉回到高斯分布的状态。
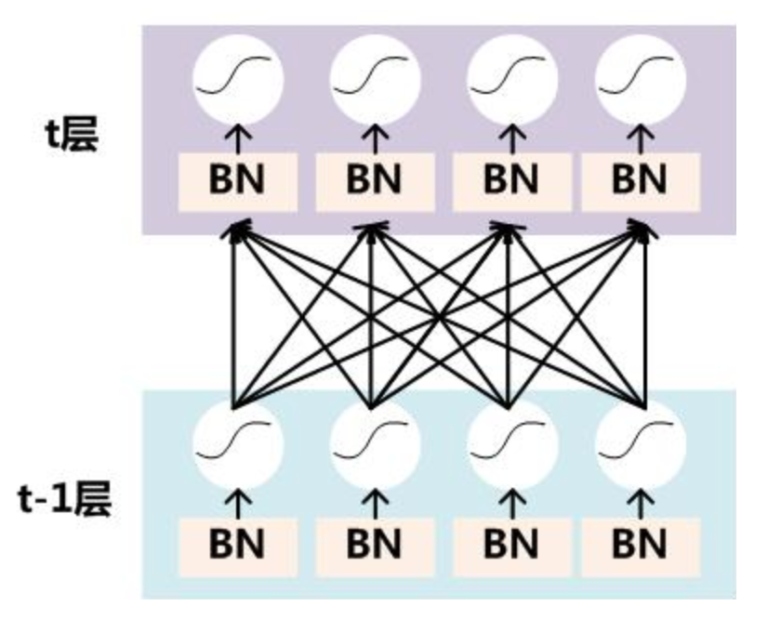
在我们从前一层得到输出之后,输出值会传给下一层做,然后a = g(z)做非线性激活。我们的Batch Normalization就卡在得到了z之后在激活函数运算之前进行。变换方法也很简单,就是把一个输入值标准化到高斯分布一样:
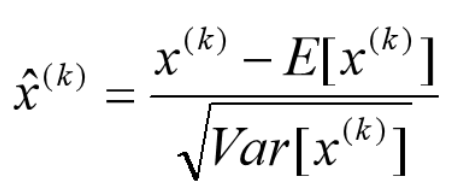
经过这个还不算完,因为强行的标准化,会导致表达能力下降,所以论文作者也提出了一种防止办法,那就是在得到新的x后,
对x进行一个转化,这个转化过程叫scale and shift:。所以总结一下,整个Batch Normalization的过程就是先计算mean和variance用来标准化,
然后把标准化的x值进行转化:

- Regularization 正则化
正则化不多说了,为了防止过拟合增大数据variance。用的多的不过L1和L2。
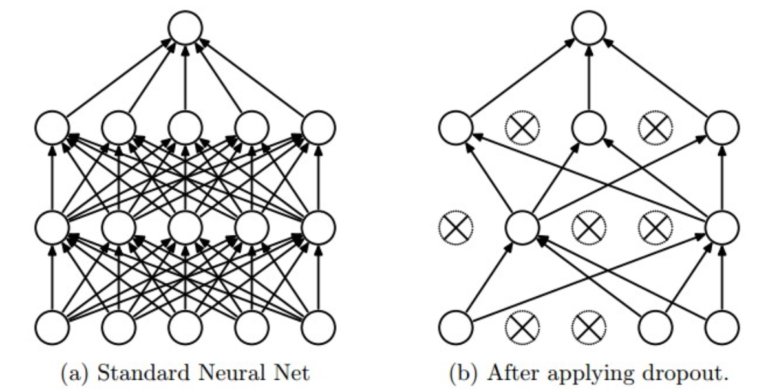
在神经网络中,还有一种防止过拟合的方法叫dropout。简单易懂易实行,就是强行的扔掉一些神经元,强行让神经网络丧失一些信息。一般dropout都是随机drop20%左右的神经元,下图中打叉的神经元就是被drop掉的。
- loss function 损失函数
我们之前介绍反向传播的时候一直说求出loss对于一些值的偏导,还没介绍过神经网络的损失函数。
对于分类问题来说,我们知道最后一层经常用的softmax层,所以损失函数就用cross-entropy loss:
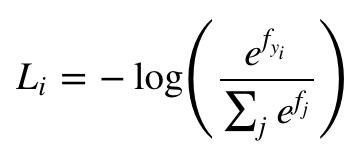
或者svm的hinge loss。但是对于label种类很多的问题,比如分1000类,我们用Hierarchical Softmax更好
对于回归问题,我们度量的就是预测值和真实值之间相差多少,就用到了L2 squared norm:
- Parameter updates 参数更新
在反向传播后我们得到了梯度,那么怎么用这些梯度来更新我们的模型参数呢?最熟知应该就是SGD了,仅仅是用更新前的参数加上负梯度即可。
我们之前接触到的梯度下降就像是一个盲人,在起点的时候先拿手杖敲敲四周看看哪里坡度最大,然后走几步。停下来又拿手杖敲敲四周,再走几步。这样周而复始的一直走到最低点。这就是普通的梯度下降法。而我们的胃口不仅仅是承认自己是个盲人,我们不仅要每次精确的定位下降方向,还要以更快的速度走到极小值。所以基于GD,还有很多优于GD的衍生算法:
- Momentum update:
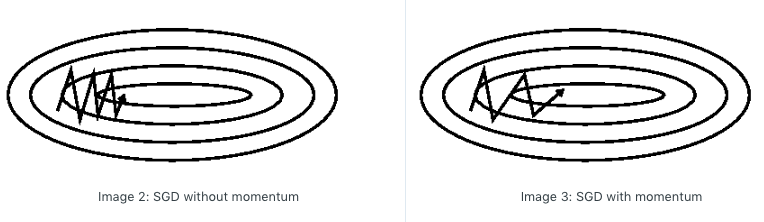
由于SGD在下降过程中容易受陡峭的梯度而产生比较严重的震荡,这样大大增加了更新速度。所以在SGD的基础上我们加上动量更新,也就是在上一步的方向上,一定程度上保留了方向,增加了一定的步长,这样使得下降的方向更明确,也就防止了过度的震荡耽误更新速度。可以想像成物理学中的加速度,这次不仅仅走一半停下来看看四周的梯度了,而是下一步的更新,在vt中汇聚了所有之前走过的动量,在这个动量的基础上再去决定下一步往哪里走。下面是动量更新的表达式,其中ϒ是我们一个超参数需要自己定义,这代表了下一步和上一步的影响大小,一般设置为0.9。
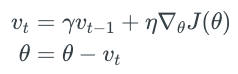
- Nesterov Momentum(Nesterov accelerated gradient,NAG):
之前的Momentum update是综合了历史的动作 + 此时的动作来推理出下一步应该怎么走。而Nesterov大牛想,我们能不能根据未来的动作 + 此时的动作来更新呢?就是先不管三七二十一先走一点,然后综合此刻的位置和未来的位置,再来判断下一步该往哪里走。这样就不单单是以史为鉴了,而是我看到马云成功了,我也要学习他。这样就有了下面的更新公式。同样的我们把ϒ一般设置为0.9。
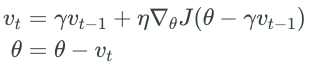
- Adagrad:
Adagrad是一种更新学习率的算法,他主导的并不是以上说的该外哪里走走多远,而是对于每个参数w的有不同的学习率。如果这个参数w的梯度很大或者它经常更新那么它的学习率就会减小,相反如果参数w的梯度很小或者说它并不经常更新,它的学习率就会增大。所以这种特性很适合于训练sparse(稀疏)的特征。
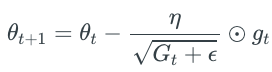
其中gt是我们当前的梯度值,Gt是我们对于学习率更新的参数,它是累加了之前所有梯度的平方。根号下的小ε是一个平滑因子,为了防止分母为0所以加一个固定的很小很小的数字,比如1e-8 。
- RMSprop:
这是Hinton大牛对于adagrad提出的更新策略,他认为adagrad在学习率下降的时候过于莽撞。于是把每次累加的梯度平方改成了梯度平方根的平均值:
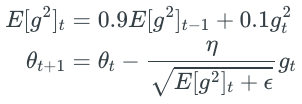
- Adam(Adaptive Moment Estimation):
这也是一种自适应学习率更新算法,它的表现通常比RMSprop好一点所以很多人默认用Adam来更新参数。它不仅仅像RMSprop计算梯度平方的平均值,而且还记录了梯度的平均值:
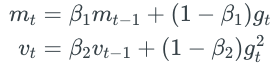
mt是梯度的平均值,叫做一阶矩;vt是梯度平方的平均值,叫做二阶矩。其中β1(例如0.9)和β2(例如0.999)很close to 1 。
这两个矩在更新的时候经常会经过一个偏移修正(bias correction mechanism):
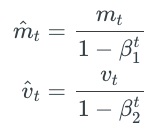
为什么修正这要从数学推导讲起了,反正我是不会。。只要知道怎么应用就好。最后我们通过修正过的一阶矩和二阶矩来更新参数:
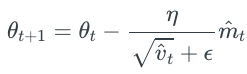
这里ε照常取一个很小的值作为平滑因子,比如1e-8 。
- Hyperparameter optimization
超参数的调参是我们建模中一个非常重要的过程,就好像赛车比赛前不仅要把装备配齐,还要把装备性能调整到最佳状态。经常用到的有两种调参方法:
- Random search
随机搜索就是在参数的取值范围内随机挑选一个参数组合,然后放到模型中尝试一下,反复比如说50次,然后挑选出一组有着最优值的参数组合。
- Grid search
网格搜索就好比for loop了,你给定几个候选值,然后它会从候选的值里for loop出来组合尝试。
相比以上两种方法,random search反而更好一些,因为在不知道超参数什么时候好什么时候不好的情况下,你给出的候选值也未必就是好的,还不如让它在范围内随机搜索一点时间。
- HyperOpt
还有一种比较新的搜索算法叫hyperopt,这种算法只提供了python库,他的原理就是在你给定了一个要优化的函数之后,通过退火等一些算法,像梯度下降一样找到使得你的函数输出最小值。如果应用在我们的模型中,我们可以把整个模型的架构作为一个函数,然后这个函数的返回值是最后准确率,因为hyperopt找的是最小值,所以我们在准确率前加一个负号。这样hyperopt找完的最小值的参数组合,也就是可以使我们的准确率最高的参数组合了。
对hyperopt感兴趣的同学可以看这篇论文 http://conference.scipy.org/proceedings/scipy2013/pdfs/bergstra_hyperopt.pdf
- Model evaluation
模型的评估就是在你做完以上所有东西后,看一看这个模型的好坏。一般会在调参的时候加上一个交叉验证(cross validation)的方法来挑选模型。
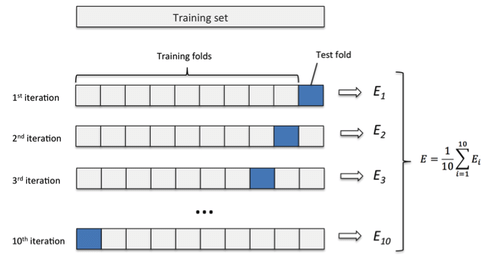
交叉验证就是把整个的数据集分成n份,每次由其中的一份作为测试集,其余的用来训练,最后你会得到n个结果,然后相加这n的结果再取mean就是在当前情况下的模型能力。然后可以再换一些别的参数或者模型再进行交叉验证,最后比较一下哪个好。